
正则表达式基础简介
. 匹配任意一个字符(非换行符)
* 匹配前一个字符出现0次或者多次
[abc] 中括号内任意一个字符
[^abc] 非中括号内的字符
[0-9] 表示一个数字
[a-z] 小写字母
[A-Z] 大写字母
[a-zA-Z] 所有字母
[a-zA-Z0-9] 所有字母+数字
[^0-9] 非数字
^xx 以xx开头
xx$ 以xx结尾
\d 任何一个数字
\s 任何一个空白字符 ? 前面字符出现0或者1次
+ 前面字符出现1或者多次
{n} 前面字符匹配n次
{a,b} 前面字符匹配a到b次
{,b} 前面字符匹配0次到b次
{a,} 前面字符匹配a或a+次
(string1|string2) string1或string2- 114.114.114.114 255.277.277.277
- 1-3个数字.1-3个数字.1-3个数字.1-3个数字
- [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
- 多提取
Logstash正则分析Nginx日志
Nginx日志说明
192.168.1.1 – – [02/May/2023:22:51:08 +0800] “GET / HTTP/1.1” 304 0 “-” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36”
- Grok使用(?<xxx>提取内容)来提取xxx字段
- 提取客户端IP: (?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})
- 提取时间: \[(?<requesttime>[^ ]+ \+[0-9]+)\]
(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"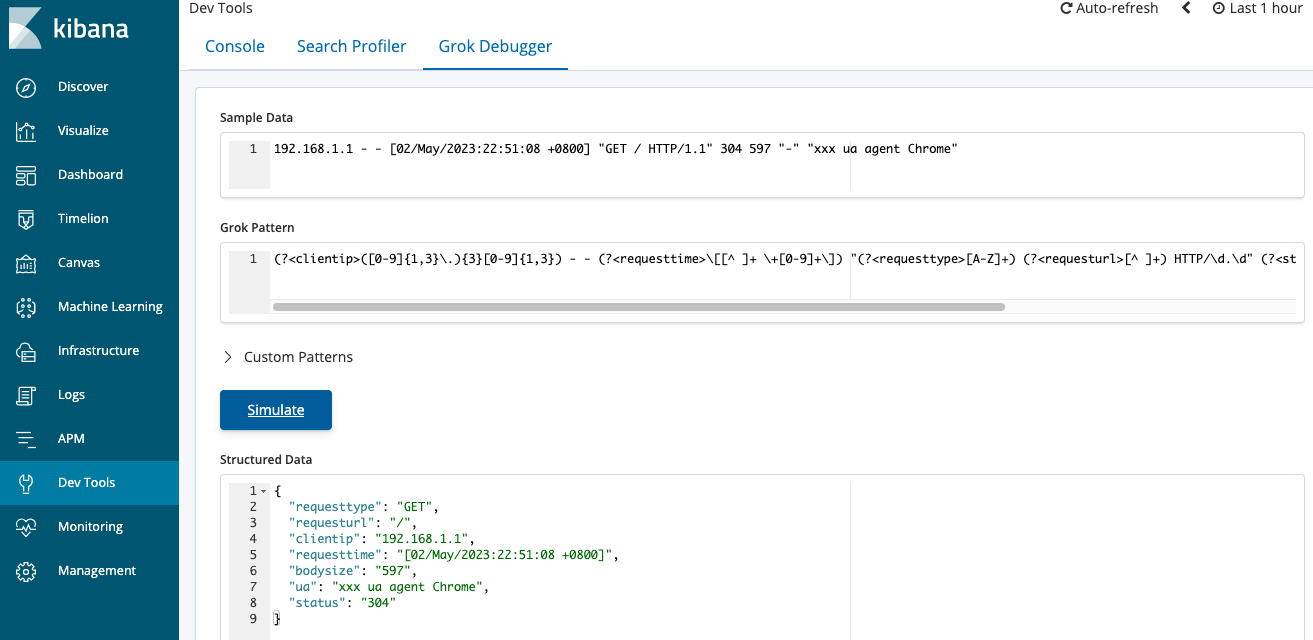
提取Tomcat等日志使用类似的方法
/usr/local/logstash-6.6.0/config/logstash.conf
input {
file {
path => "/usr/local/nginx/logs/access.log"
}
}
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.1.10:9200"]
}
}
kill -1 $(ps aux | grep logstash | grep -v grep | awk ‘{print $2}’ | head -1)
访问几次nginx网页

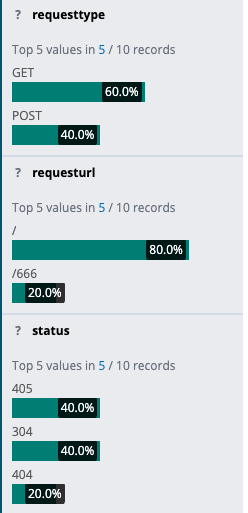
echo “1111” >> /usr/local/nginx/logs/access.log
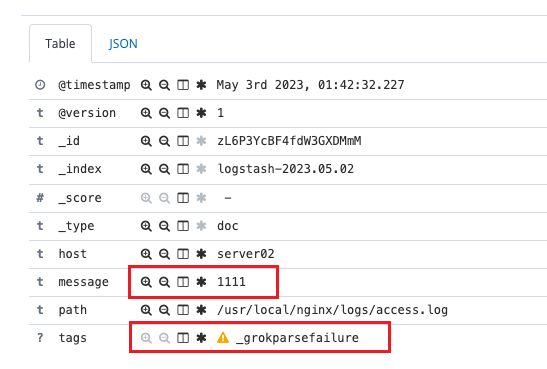
output{
if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] {
elasticsearch {
hosts => ["http://192.168.1.10:9200"]
}
}
}
Logstash去除不需要的字段
去除字段注意
Logstash配置去除不需要的字段 /usr/local/logstash-6.6.0/config/logstash.conf
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
}
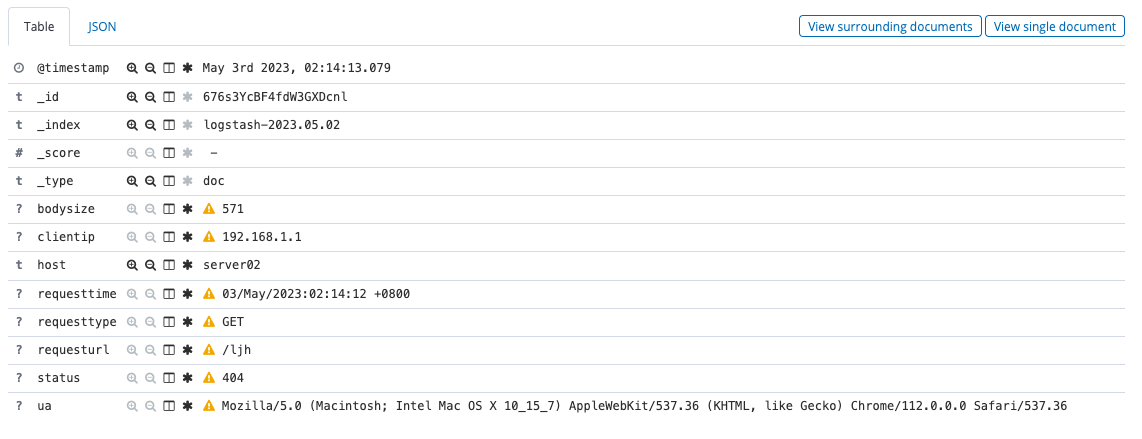
“message”,”@version”,”path”这三个字段已经不显示了
去除字段优势:
ELK覆盖时间轴和全量分析
默认ELK时间轴
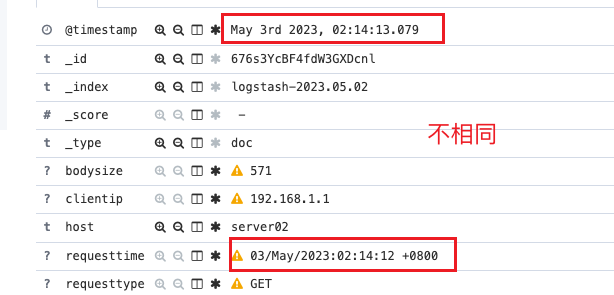
Logstash全量分析所有Nginx日志,如果延迟过高,nginx的日志和kibana上显示的出入会非常大,所以用requesttime去覆盖timestamp
input {
file {
path => "/usr/local/nginx/logs/access.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
Logstash的filter里面加入配置24/Feb/2019:21:08:34 +0800
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
date {
match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
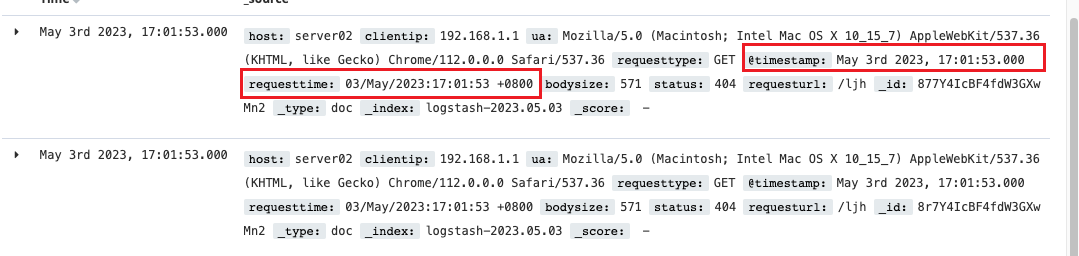
cat /usr/local/nginx/logs/access.log |awk ‘{print $4}’|cut -b 1-19|sort |uniq -c
发布者:LJH,转发请注明出处:https://www.ljh.cool/37111.html
