
我们在前面已经了解到,为了支持集群的水平扩展、高可用性,Kubernetes抽象出了Service的概念。Service是对一组Pod的抽象,它会根据访问策略(如负载均衡策略)来访问这组Pod。
Kubernetes在创建服务时会为服务分配一个虚拟的IP地址,客户端通过访问这个虚拟的IP地址来访问服务,服务则负责将请求转发到后端的Pod上。这不就是一个反向代理吗?没错,这就是一个反向代理。但是,它和普通的反向代理有一些不同:首先,它的IP地址是虚拟的,想从外面访问还需要一些技巧;其次,它的部署和启停是由Kubernetes统一自动管理的。
在很多情况下,Service只是一个概念,而真正将Service的作用落实的是它背后的kube-proxy服务进程。只有理解了kube-proxy的原理和机制,我们才能真正理解Service背后的实现逻辑。
在Kubernetes集群的每个Node上都会运行一个kube-proxy服务进程,我们可以把这个进程看作Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上。此外,Service的Cluster IP与NodePort等概念是kube-proxy服务通过iptables的NAT转换实现的,kube-proxy在运行过程中动态创建与Service相关的iptables规则,这些规则实现了将访问服务(Cluster IP或NodePort)的请求负载分发到后端Pod的功能。由于iptables机制针对的是本地的kube-proxy端口,所以在每个Node上都要运行kube-proxy组件,这样一来,在Kubernetes集群内部,我们可以在任意Node上发起对Service的访问请求。综上所述,由于kube-proxy的作用,在Service的调用过程中客户端无须关心后端有几个Pod,中间过程的通信、负载均衡及故障恢复都是透明的。
起初,kube-proxy进程是一个真实的TCP/UDP代理,类似HA Proxy,负责从Service到Pod的访问流量的转发,这种模式被称为userspace(用户空间代理)模式。如图所示,当某个Pod以Cluster IP方式访问某个Service的时候,这个流量会被Pod所在本机的iptables转发到本机的kube-proxy进程,然后由kube-proxy建立起到后端Pod的TCP/UDP连接,随后将请求转发到某个后端Pod上,并在这个过程中实现负载均衡功能。
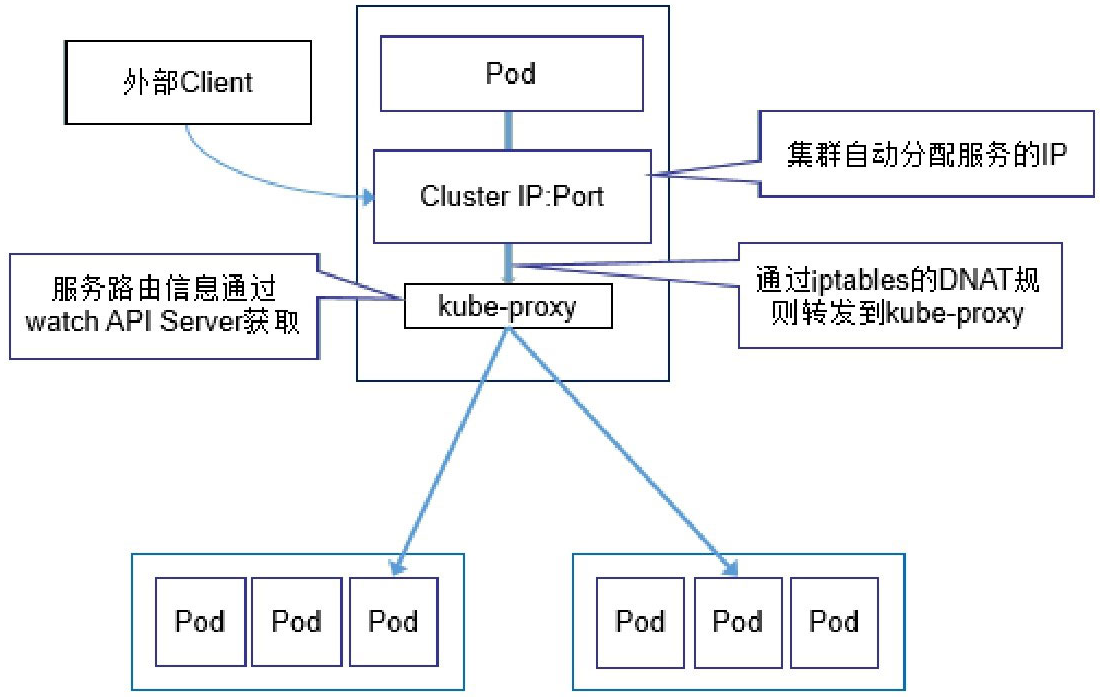

关于Cluster IP与Node Port的实现原理,以及kube-proxy与API Server的交互过程,下图给出了较为详细的说明,由于这是最古老的kube-proxy的实现方式,所以不再赘述。

如下图所示,Kubernetes从1.2版本开始,将iptables作为kube-proxy的默认模式。iptables模式下的kube-proxy不再起到Proxy的作用,其核心功能:通过API Server的Watch接口实时跟踪Service与Endpoint的变更信息,并更新对应的iptables规则,Client的请求流量则通过iptables的NAT机制“直接路由”到目标Pod。
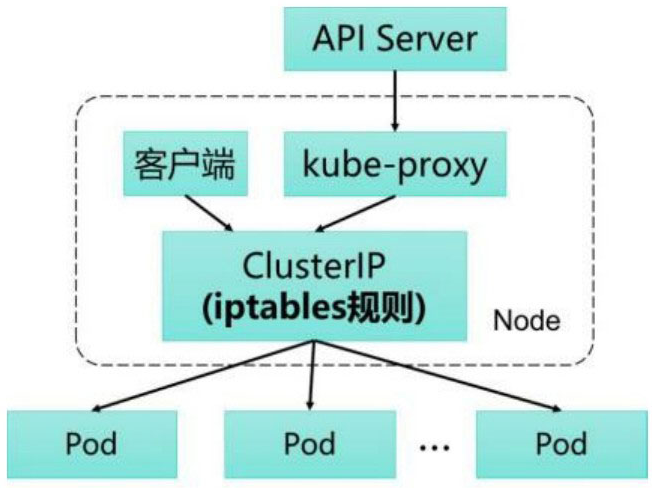
根据Kubernetes的网络模型,一个Node上的Pod与其他Node上的Pod应该能够直接建立双向的TCP/IP通信通道,所以如果直接修改iptables规则,则也可以实现kube-proxy的功能,只不过后者更加高端,因为是全自动模式的。与第1代的userspace模式相比,iptables模式完全工作在内核态,不用再经过用户态的kube-proxy中转,因而性能更强。
iptables模式虽然实现起来简单,但存在无法避免的缺陷:在集群中的Service和Pod大量增加以后,iptables中的规则会急速膨胀,导致性能显著下降,在某些极端情况下甚至会出现规则丢失的情况,并且这种故障难以重现与排查,于是Kubernetes从1.8版本开始引入第3代的IPVS(IP Virtual Server)模式,如下图所示。IPVS在Kubernetes 1.11中升级为GA稳定版。
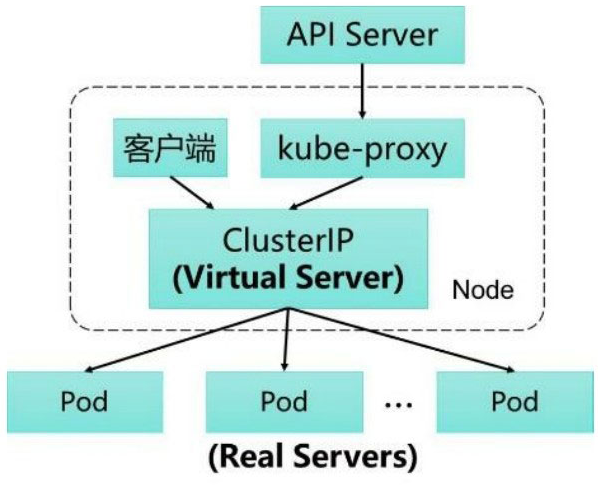
iptables与IPVS虽然都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张,因此被kube-proxy采纳为第三代模式。
与iptables相比,IPVS拥有以下明显优势:
- ◎ 为大型集群提供了更好的可扩展性和性能;
- ◎ 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
- ◎ 支持服务器健康检查和连接重试等功能;
- ◎ 可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。
ipset
由于IPVS无法提供包过滤、airpin-masquerade tricks(地址伪装)、SNAT等功能(linux 内核原生的 ipvs 模式只支持 DNAT,不支持 SNAT),因此在某些场景(如NodePort的实现)下还要与iptables搭配使用。在IPVS模式下,kube-proxy又做了重要的升级,即使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。
IP sets 是 Linux 内核中的一个框架,可以由 ipset 命令进行管理。根据不同的类型,IP set 可以以某种方式保存 IP地址、网络、(TCP/UDP)端口号、MAC地址、接口名或它们的组合,并且能够快速匹配。
根据官网的介绍,若有以下使用场景:
- 在保存了多个 IP 地址或端口号的 iptables 规则集合中想使用哈希查找;
- 根据 IP 地址或端口动态更新 iptables 规则时希望在性能上无损;
- 在使用 iptables 工具创建一个基于 IP 地址和端口的复杂规则时觉得非常繁琐;
此时,使用 ipset 工具可能是你最好的选择。
ipset 是 iptables 的一种扩展,在 iptables 中可以使用-m set启用 ipset 模块,具体来说,ipvs 使用 ipset 来存储需要 NAT 或 masquared 时的 ip 和端口列表。在数据包过滤过程中,首先遍历 iptables 规则,在定义了使用 ipset 的条件下会跳转到 ipset 列表中进行匹配。
iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹配。我们可以将ipset简单理解为一个IP(段)的集合,这个集合的内容可以是IP地址、IP网段、端口等,iptables可以直接添加规则对这个“可变的集合”进行操作,这样做的好处在于可以大大减少iptables规则的数量,从而减少性能损耗。
假设要禁止上万个IP访问我们的服务器,则用iptables的话,就需要一条一条地添加规则,会在iptables中生成大量的规则;但是用ipset的话,只需将相关的IP地址(网段)加入ipset集合中即可,这样只需设置少量的iptables规则即可实现目标。
kube-proxy针对Service和Pod创建的一些主要的iptables规则如下。
- ◎ KUBE-CLUSTER-IP:在masquerade-all=true或clusterCIDR指定的情况下对Service Cluster IP地址进行伪装,以解决数据包欺骗问题。
- ◎ KUBE-EXTERNAL-IP:将数据包伪装成Service的外部IP地址。
- ◎ KUBE-LOAD-BALANCER 、 KUBE-LOAD-BALANCER-LOCAL :伪装Load Balancer类型的Service流量。
- ◎ KUBE-NODE-PORT-TCP、KUBE-NODE-PORT-LOCAL-TCP、KUBE-NODE-PORT-UDP、KUBE-NODE-PORT-LOCAL-UDP:伪装NodePort类型的Service流量。
发布者:LJH,转发请注明出处:https://www.ljh.cool/40526.html
评论列表(1条)
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.com/es-MX/register?ref=GJY4VW8W