
元组
在 Python 中,元组(tuple)是一种用于存储多个项目的内置数据类型。元组与列表相似,以下是元祖的特点:
- 不可变性:元组一旦创建,其内容就无法更改。这意味着你不能修改、添加或删除元组中的元素。
- 使用小括号:元组是用小括号
()定义的,而列表是用方括号[]。 - 可以存储不同类型的数据:元组可以包含不同类型的数据,比如整数、字符串、浮点数,甚至可以包含其他元组、列表等。
- 有序:元组是有序的集合,这意味着元素有一个定义好的顺序,每个元素可以通过索引访问。
创建一个简单的元组的例子如下:
my_tuple = (1, 2, 3, "Hello", 5.0)
元组的定义和下标使用
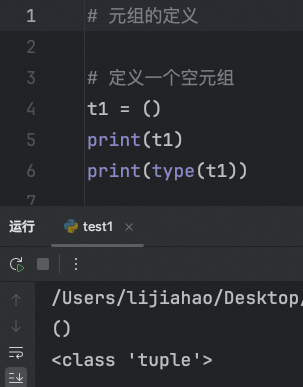
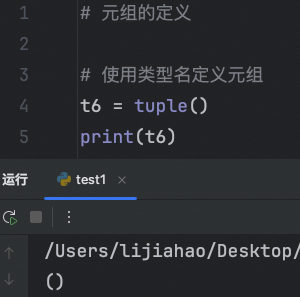
定义一个空元组

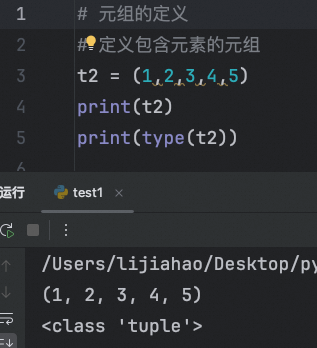
定义包含元素的元组
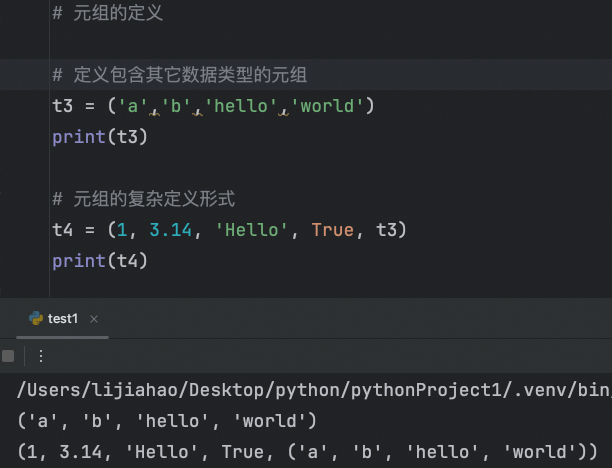
元祖的复杂定义形式
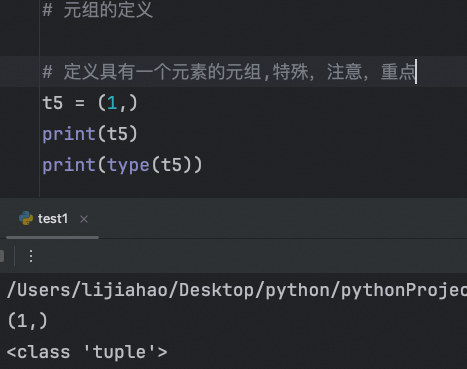
定义具有一个元素的元组,特殊,注意,重点
使用类型名定义元组
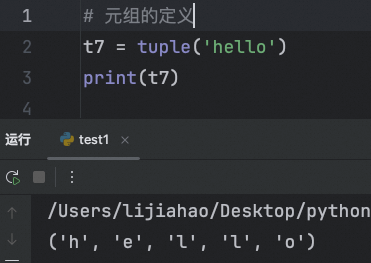
字符串放入到元祖中,元祖会将字符串迭代出来
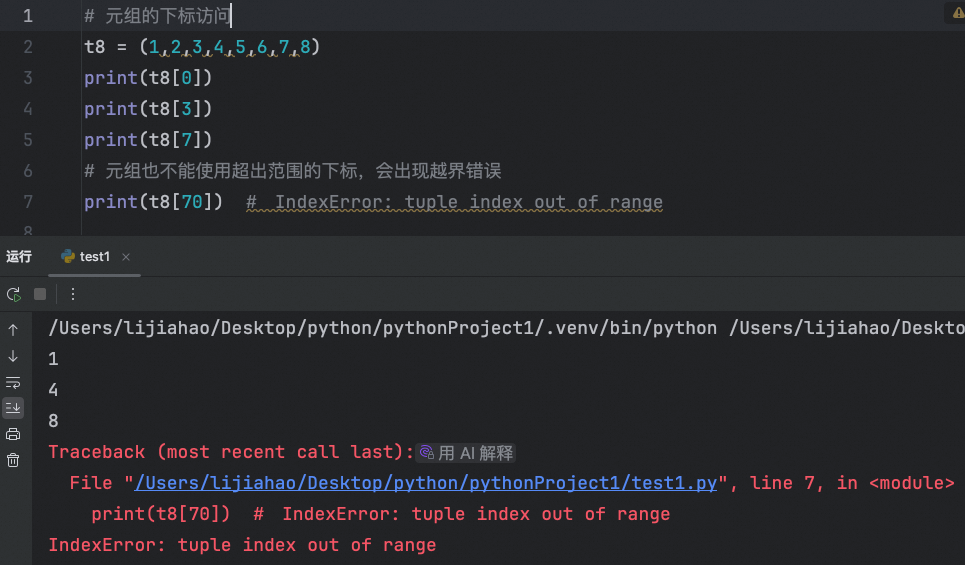
元组的下标访问,元组也不能使用超出范围的下标,会出现越界错误
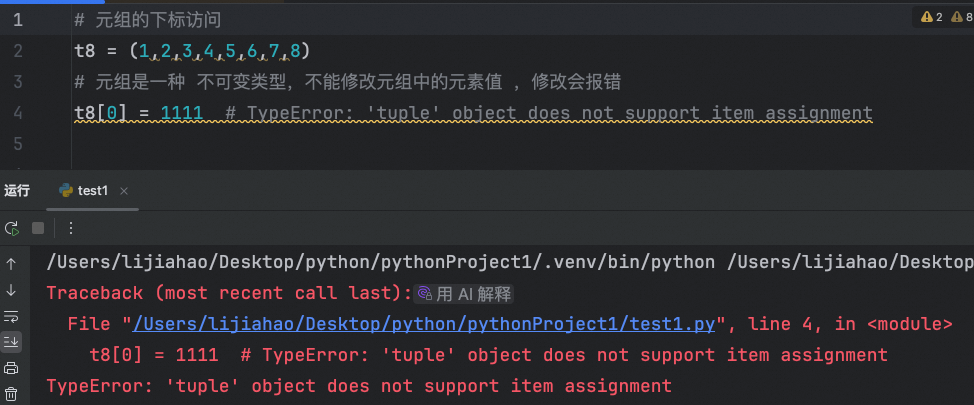
元组是一种 不可变类型,不能修改元组中的元素值 ,修改会报错
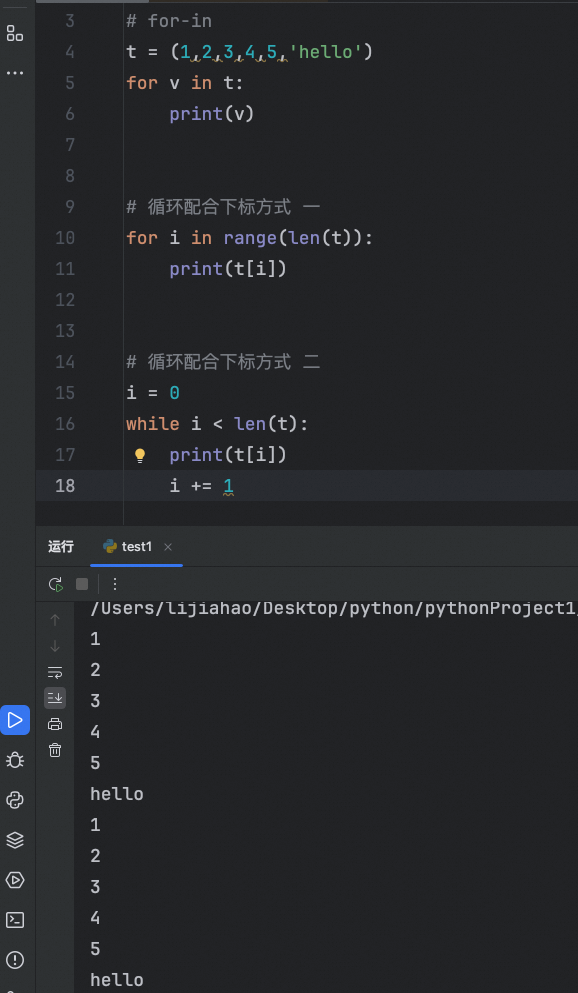
元祖的遍历
# 元组的遍历
# for-in
t = (1,2,3,4,5,'hello')
for v in t:
print(v)
# 循环配合下标方式 一
for i in range(len(t)):
print(t[i])
# 循环配合下标方式 二
i = 0
while i < len(t):
print(t[i])
i += 1
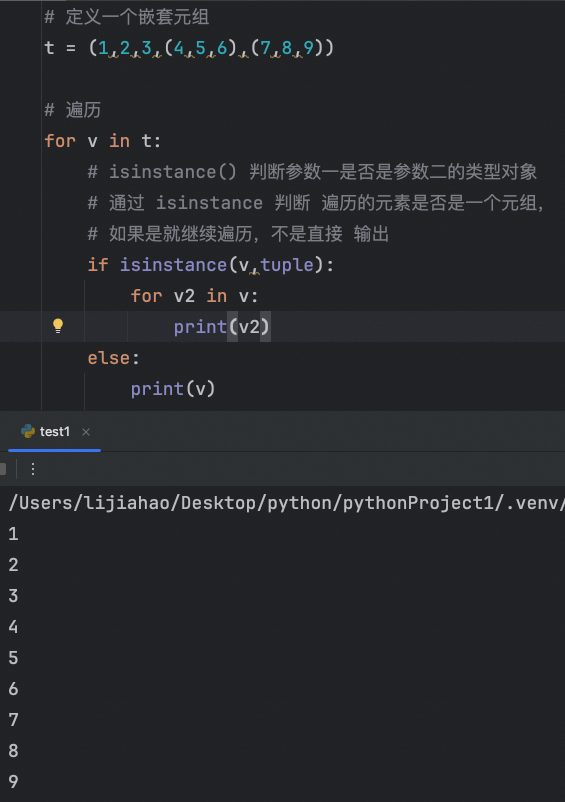
嵌套元祖的定义和遍历
通过 isinstance 判断 遍历的元素是否是一个元组
# 定义一个嵌套元组
t = (1,2,3,(4,5,6),(7,8,9))
# 遍历
for v in t:
# isinstance() 判断参数一是否是参数二的类型对象
# 通过 isinstance 判断 遍历的元素是否是一个元组,
# 如果是就继续遍历,不是直接 输出
if isinstance(v,tuple):
for v2 in v:
print(v2)
else:
print(v)
补充:
isinstance() 是一个内置函数,用于检查一个对象是否是指定类的实例,或者是否是该类的子类的实例。它的语法是:
isinstance() 返回 True 如果对象是 classinfo 的一个实例,或者是其子类的一个实例;否则返回 False。
# 检查一个变量是否是整数类型
x = 10
print(isinstance(x, int)) # 输出: True
# 检查一个变量是否是元组中指定的类型之一
y = 3.14
print(isinstance(y, (int, float))) # 输出: True
# 自定义类的例子
class Animal:
pass
class Dog(Animal):
pass
d = Dog()
print(isinstance(d, Dog)) # 输出: True
print(isinstance(d, Animal)) # 输出: True
在上述例子中,isinstance() 可用于检查对象的类型关系,特别是在继承层次结构中,它比单纯使用类型比较更灵活。
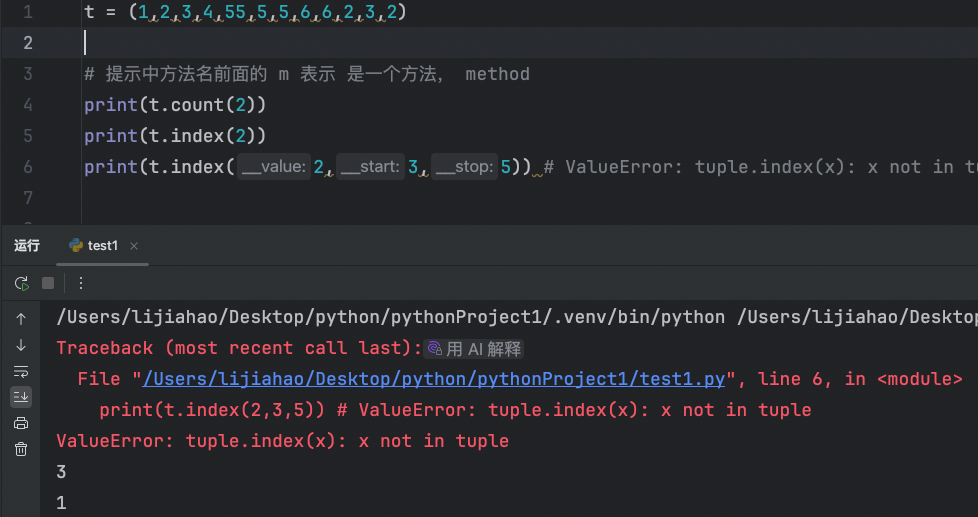
元组的常用方法
查
统计元素个数和查找元素的位置索引
t = (1,2,3,4,55,5,5,6,6,2,3,2) # 提示中方法名前面的 m 表示 是一个方法, method print(t.count(2)) print(t.index(2)) print(t.index(2,3,5)) # ValueError: tuple.index(x): x not in tuple
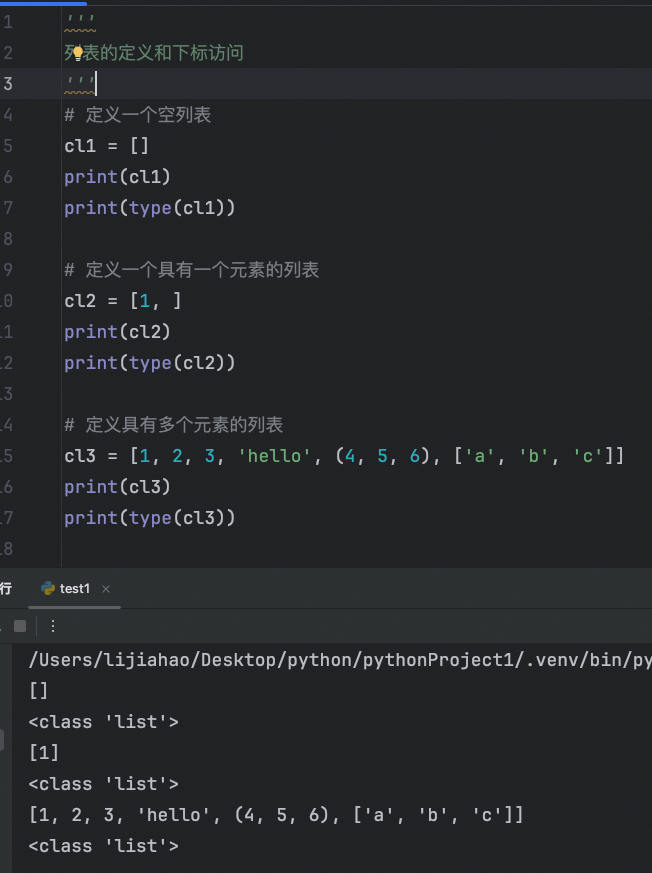
列表
列表的定义和下标使用
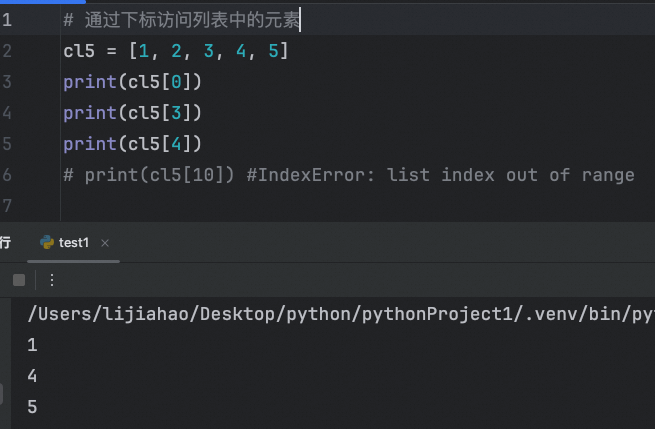
列表定义
下标使用
列表遍历
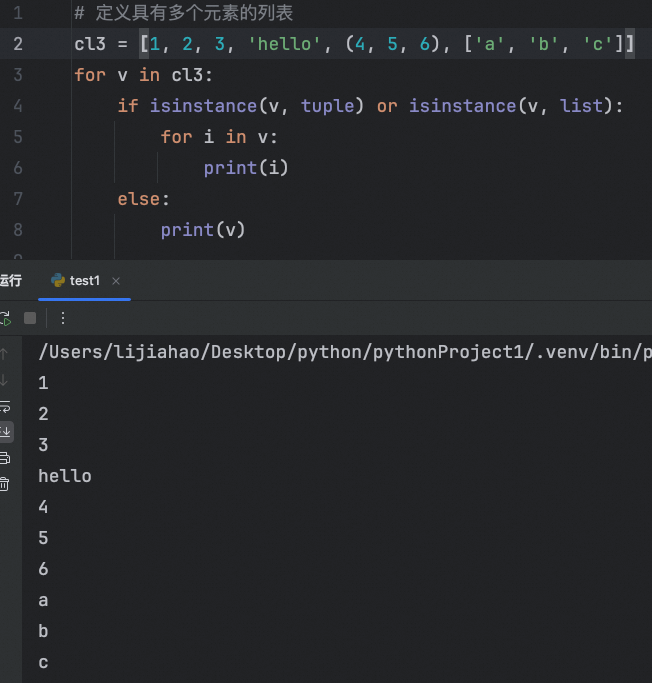
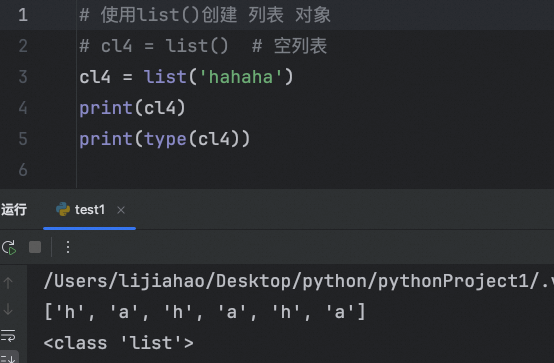
字符串放入到列表中,列表会将字符串迭代出来
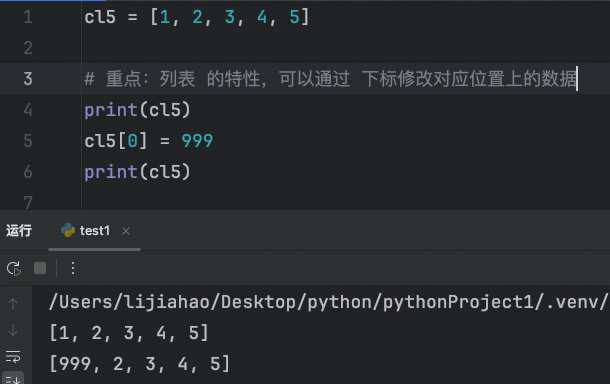
重点:列表的特性,可以通过 下标修改对应位置上的数据
列表的排序和逆序
在列表排序和逆序之前,我们先看一下字符串的排序和逆序思路:
s='hello'
def revers_str(s):
# 定义一个空字符串,用来拼接
ret_s=''
i=len(s)-1
while i >= 0:
ret_s+=s[i]
i-=1
return ret_s
print(revers_str(s))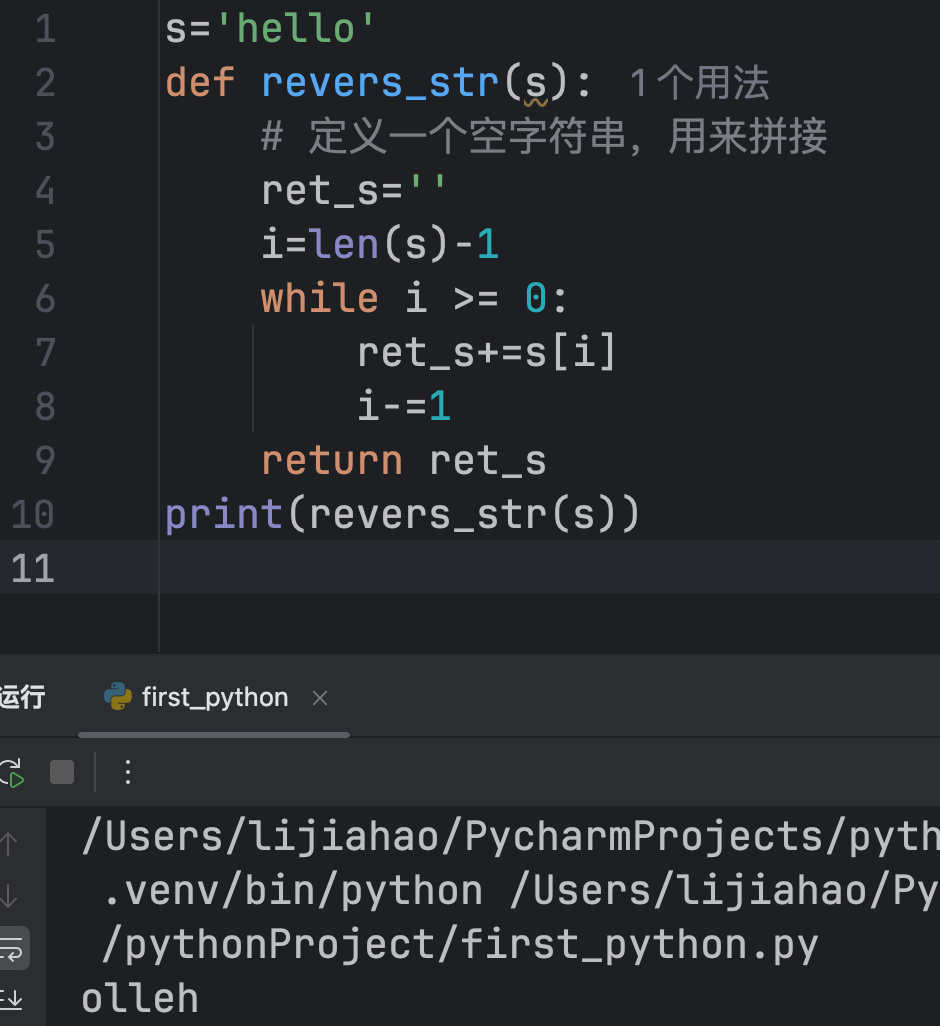
但是此时我们学习了列表,列表有一个逆序的函数可以直接使用
'''
列表的排序和逆序
'''
cl = [9,2,5,7,1,8,4,3,0,6]
print(cl)
# 排序 默认升序排序(从小到大),列表为可变数据,列表排序后改变了原来的顺序,因为已经改变了原有数据,无需进行打印,所以默认返回为空
print(cl.sort())
print(cl)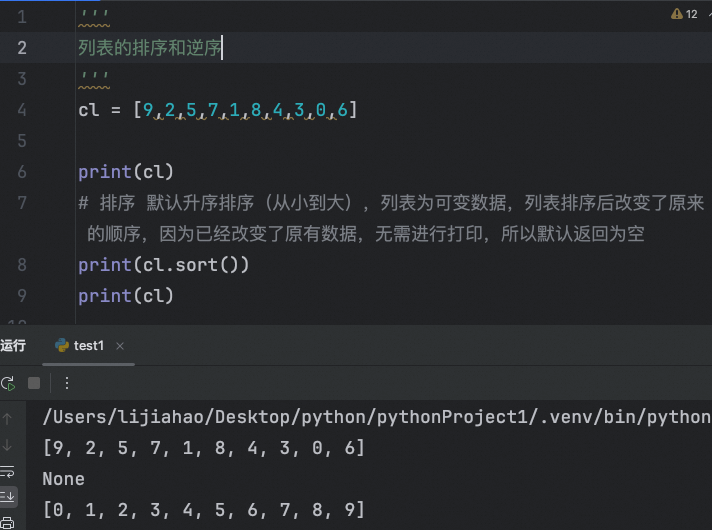
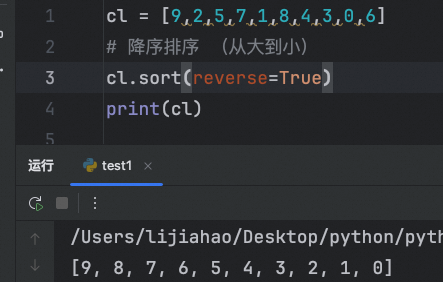
降序排序
逆序排序(直接将元列表中的顺序进行逆转,注意区别于降序排序)
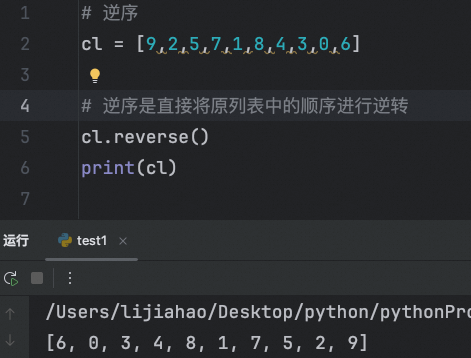
由此我们可以推断reverse()函数的由来
cl = [9,2,5,7,1,8,4,3,0,6]
def reverse_list(cl):
# 定义一个空列表
ret_l=[]
i=len(cl)-1
while i>=0:
ret_l.append(cl[i])
i-=1
return ret_l
print(reverse_list(cl))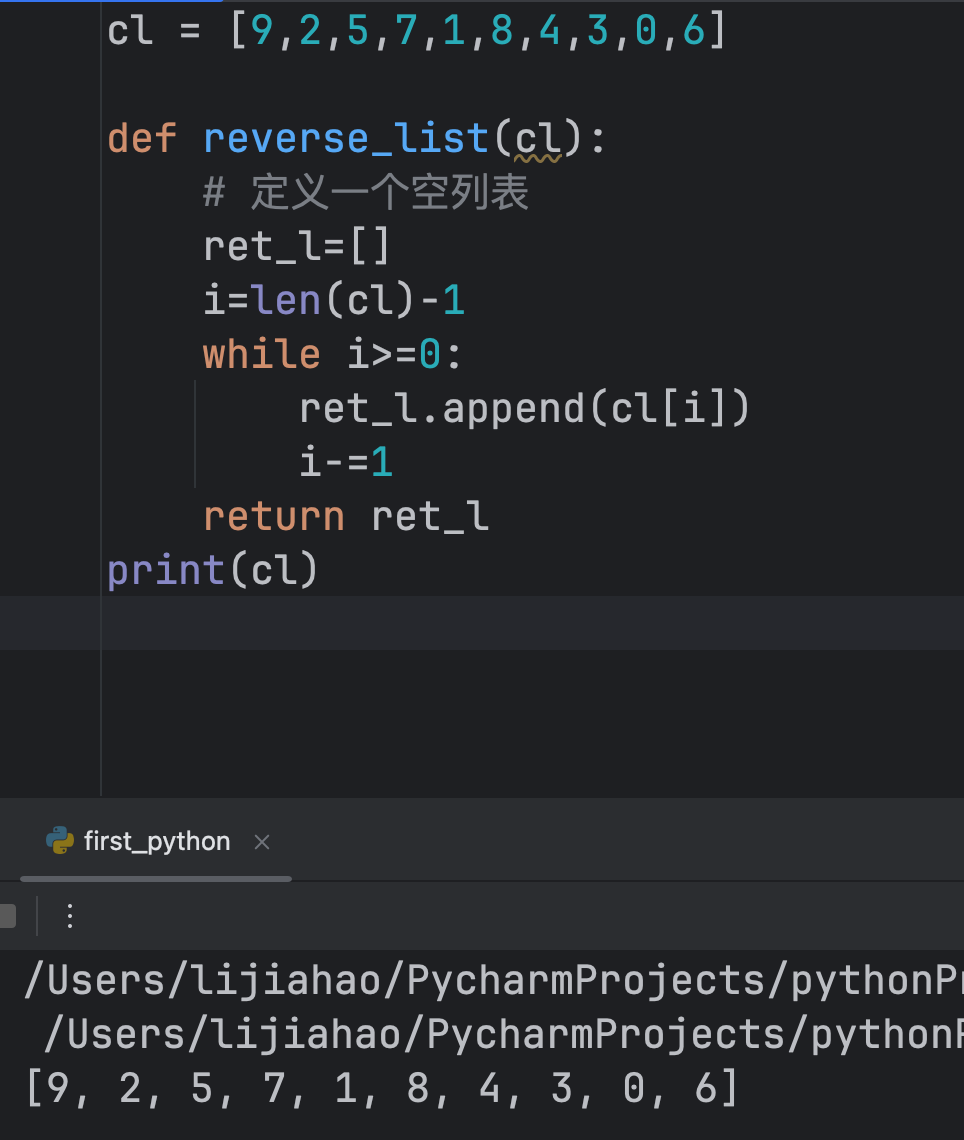
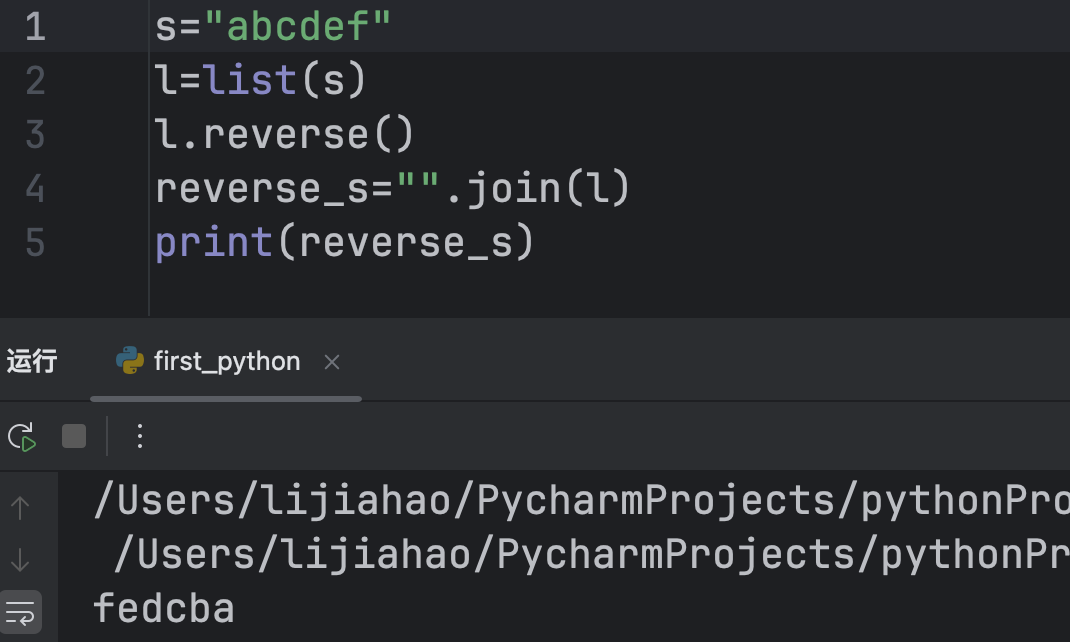
逆序字符串可以先将字符串转换为列表,然后直接使用reverse()转换
reverse()实现原理:
在 Python 内部,reverse() 通过类似的方法完成列表反转的操作,但它是原地修改列表,也就是说它不返回新列表,而是直接修改原列表。
初始状态:
left = 0, right = 4
lst = [1, 2, 3, 4, 5]
第一次交换:
交换 lst[0] 和 lst[4],即交换 1 和 5。
更新后的列表:[5, 2, 3, 4, 1]。
左指针移动:left = 1,右指针移动:right = 3。
第二次交换:
交换 lst[1] 和 lst[3],即交换 2 和 4。
更新后的列表:[5, 4, 3, 2, 1]。
左指针移动:left = 2,右指针移动:right = 2。
由于此时左指针与右指针相遇(left >= right),算法终止。
最终列表:[5, 4, 3, 2, 1]。伪代码实现
def reverse(lst):
left = 0
right = len(lst) - 1
while left < right:
# 交换左指针和右指针所指向的元素
lst[left], lst[right] = lst[right], lst[left]
# 更新指针
left += 1
right -= 1常用方法
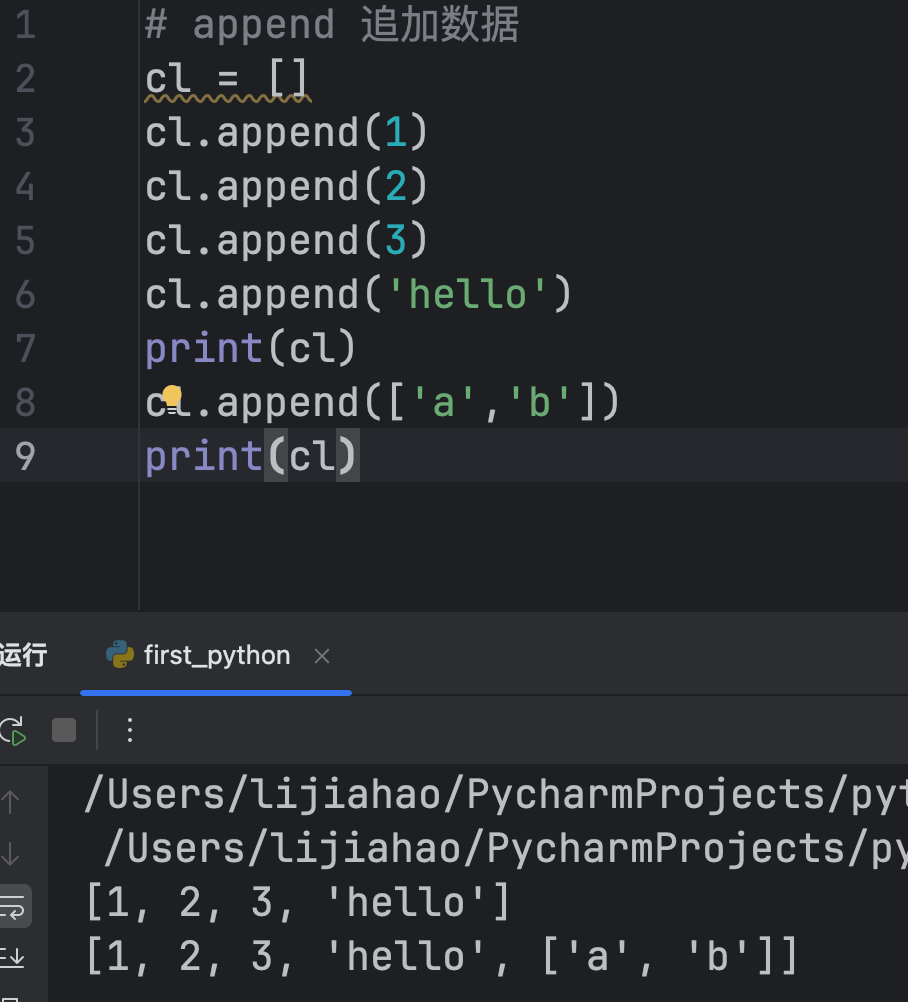
增
append() 追加数据(单个元素)
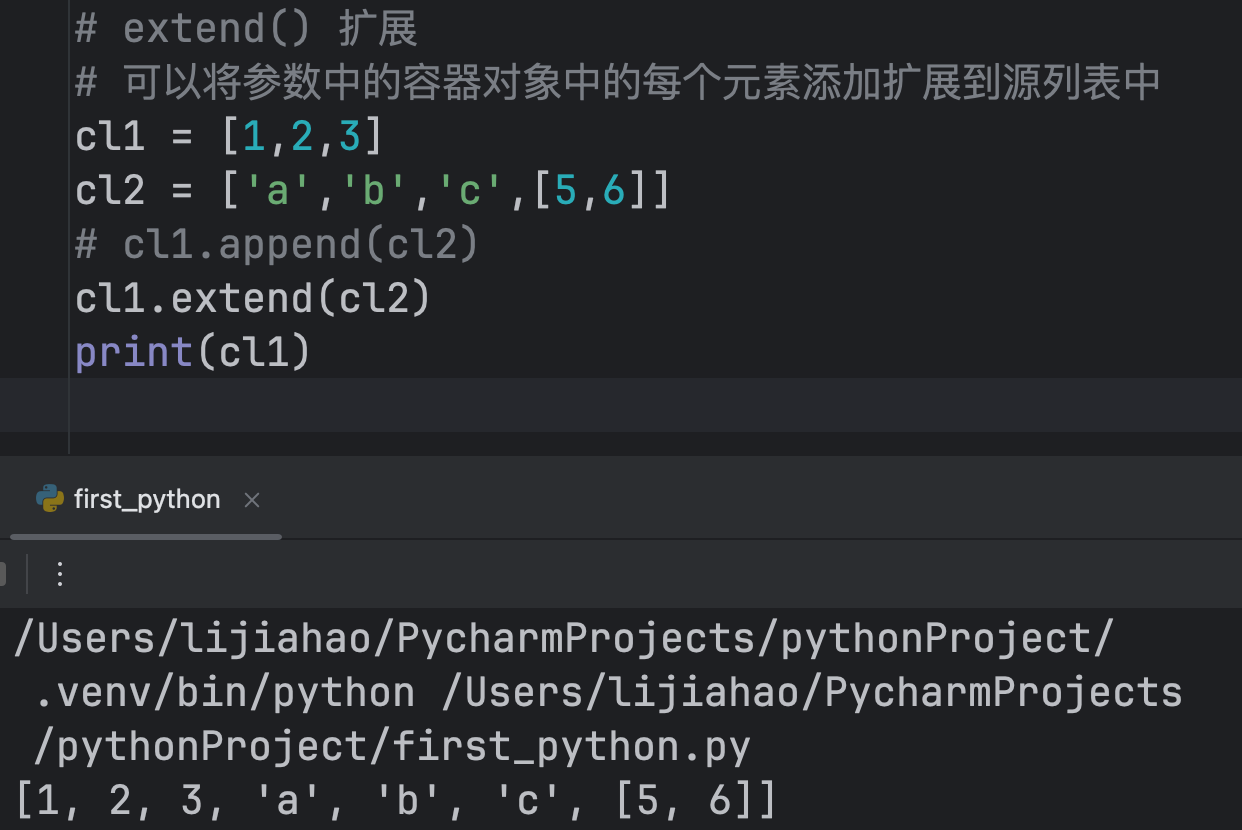
extend() 可以将参数中的容器对象中的每个元素添加扩展到源列表中
# extend() 扩展 # 可以将参数中的容器对象中的每个元素添加扩展到源列表中 cl1 = [1,2,3] cl2 = ['a','b','c',[5,6]] # cl1.append(cl2) cl1.extend(cl2) print(cl1)
insert()
格式:list.insert(index, element)
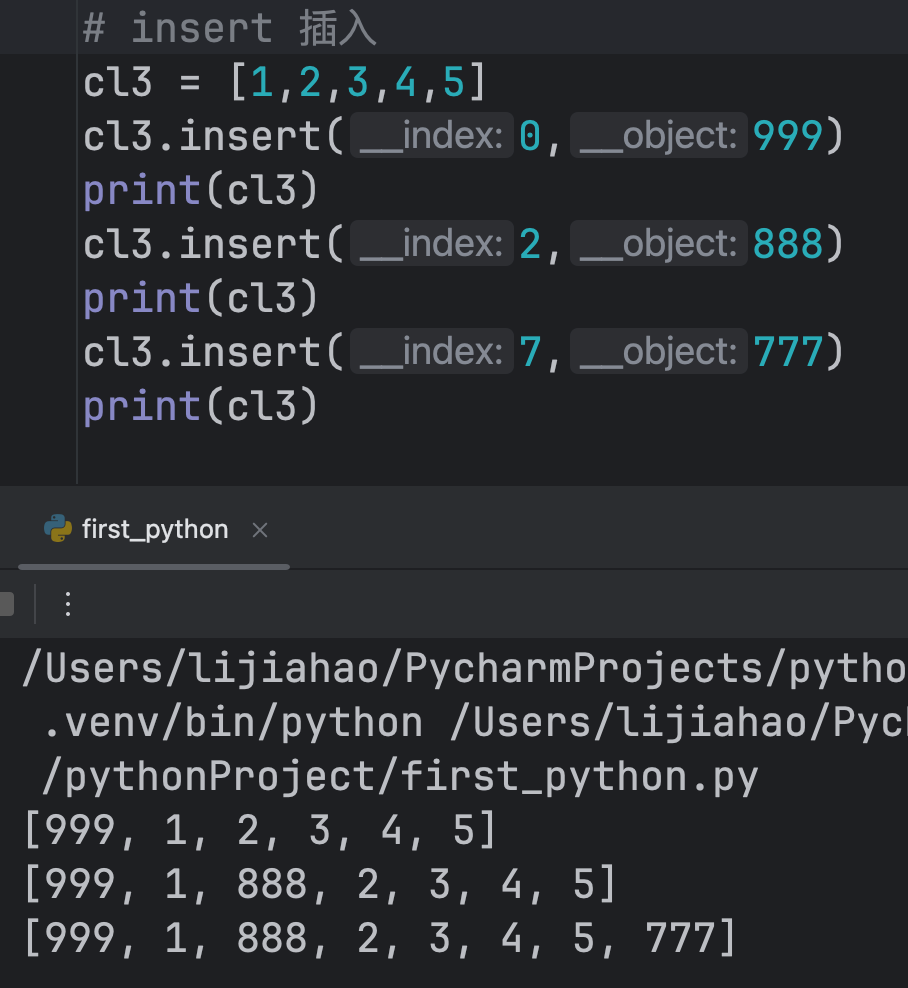
边界情况:注意:在插入数据时,没有下标越界问题
索引越界:如果指定的 index 小于 0 或大于列表的长度,元素会被追加到列表的末尾。
my_list = [1, 2, 3]
my_list.insert(5, 'out_of_bounds') # 索引 5 超过了列表的长度
print(my_list) # 输出: [1, 2, 3, 'out_of_bounds']插入空元素:如果你插入 None 或者一个空的元素,也会按指定位置插入。
my_list = [1, 2, 3]
my_list.insert(1, None) # 在索引1的位置插入 None
print(my_list) # 输出: [1, None, 2, 3]原理:链表从中间插入数据
改
下标修改
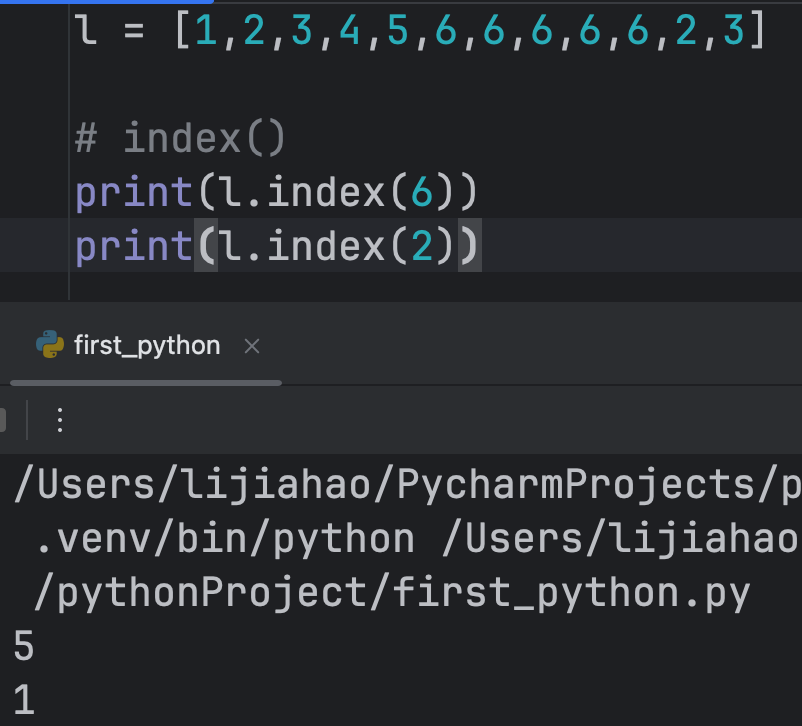
查
index()
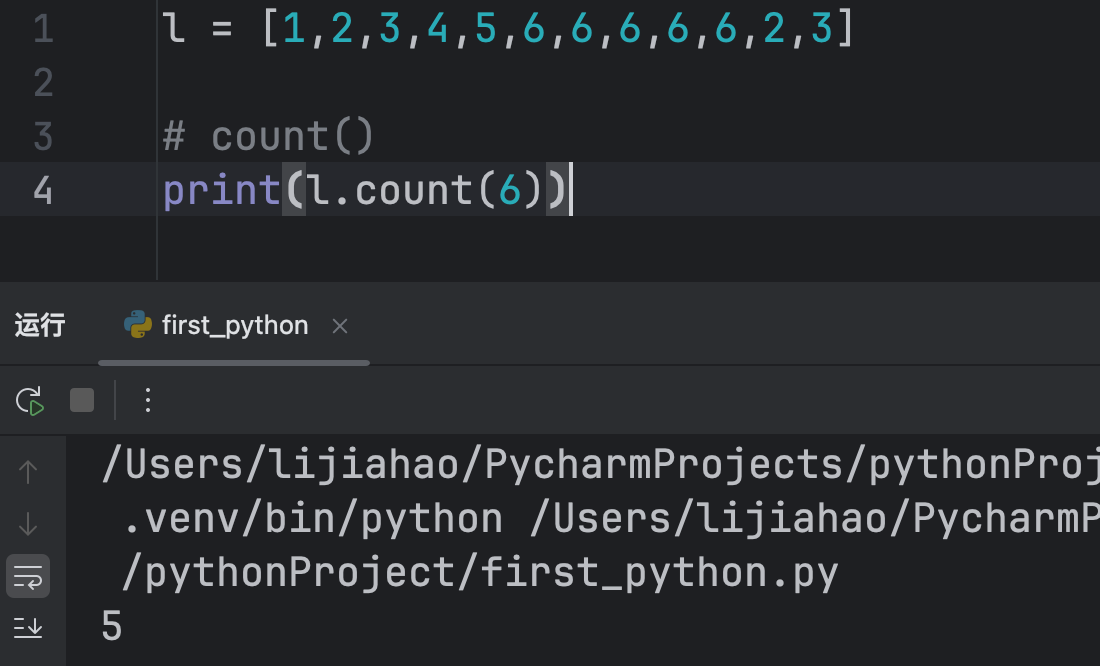
count()
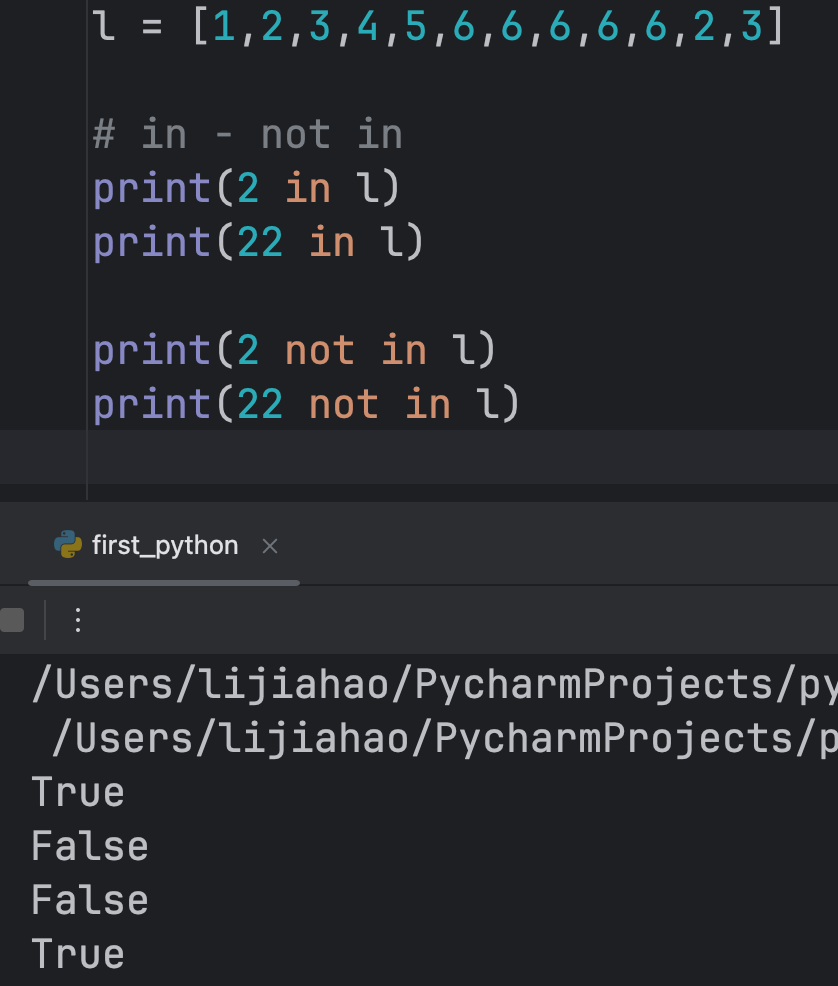
in && not in
删
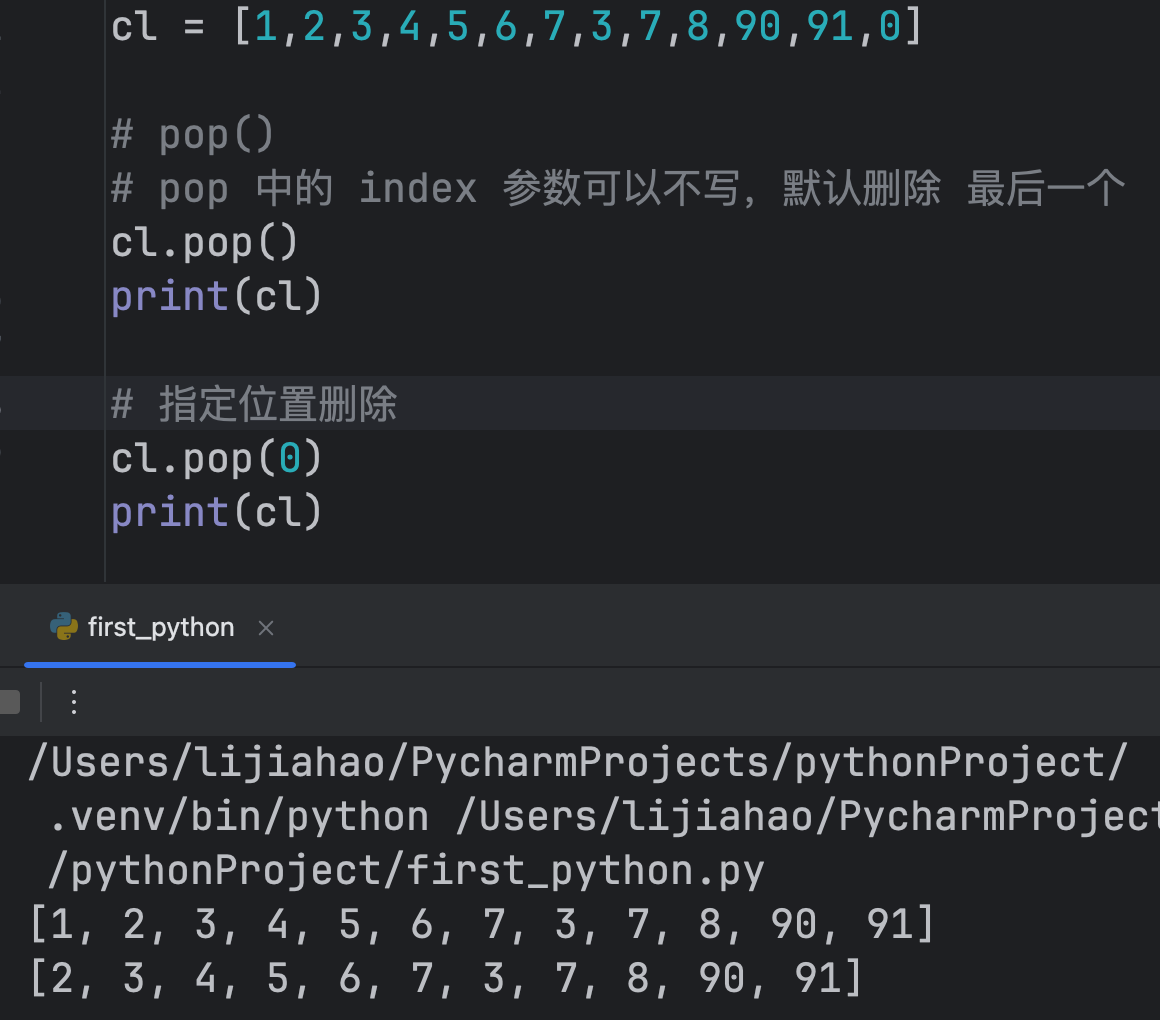
pop()
格式:list.pop([index])
index(可选):指定要删除的元素的索引位置。
如果 index 超出列表的范围,会引发 IndexError 错误。
如果不指定 index,则默认移除最后一个元素。
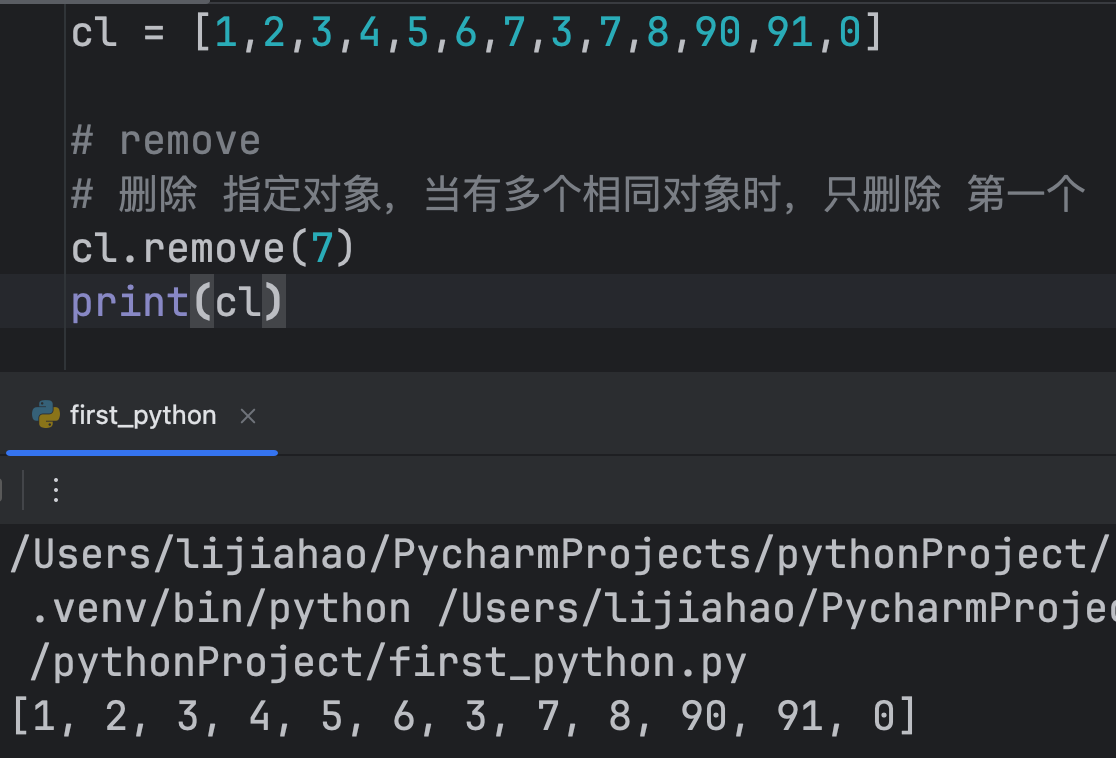
remove()
删除 指定对象,当有多个相同对象时,只删除 第一个
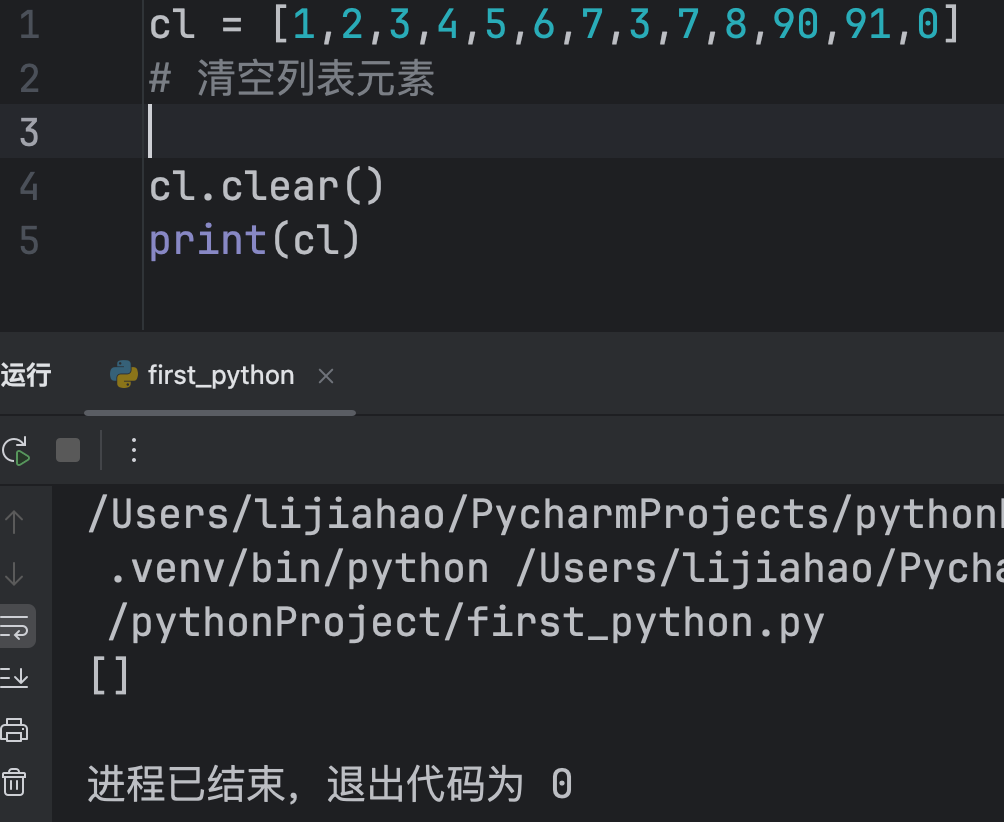
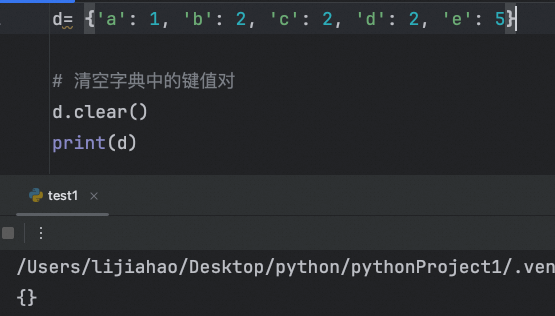
clear()
清空列表元素
del
cl = [1,2,3,4,5,6,7,3,7,8,90,91,0]
# del 删除角标写法有两种方式
del cl[1]
print(cl)
del(cl[1])
print(cl)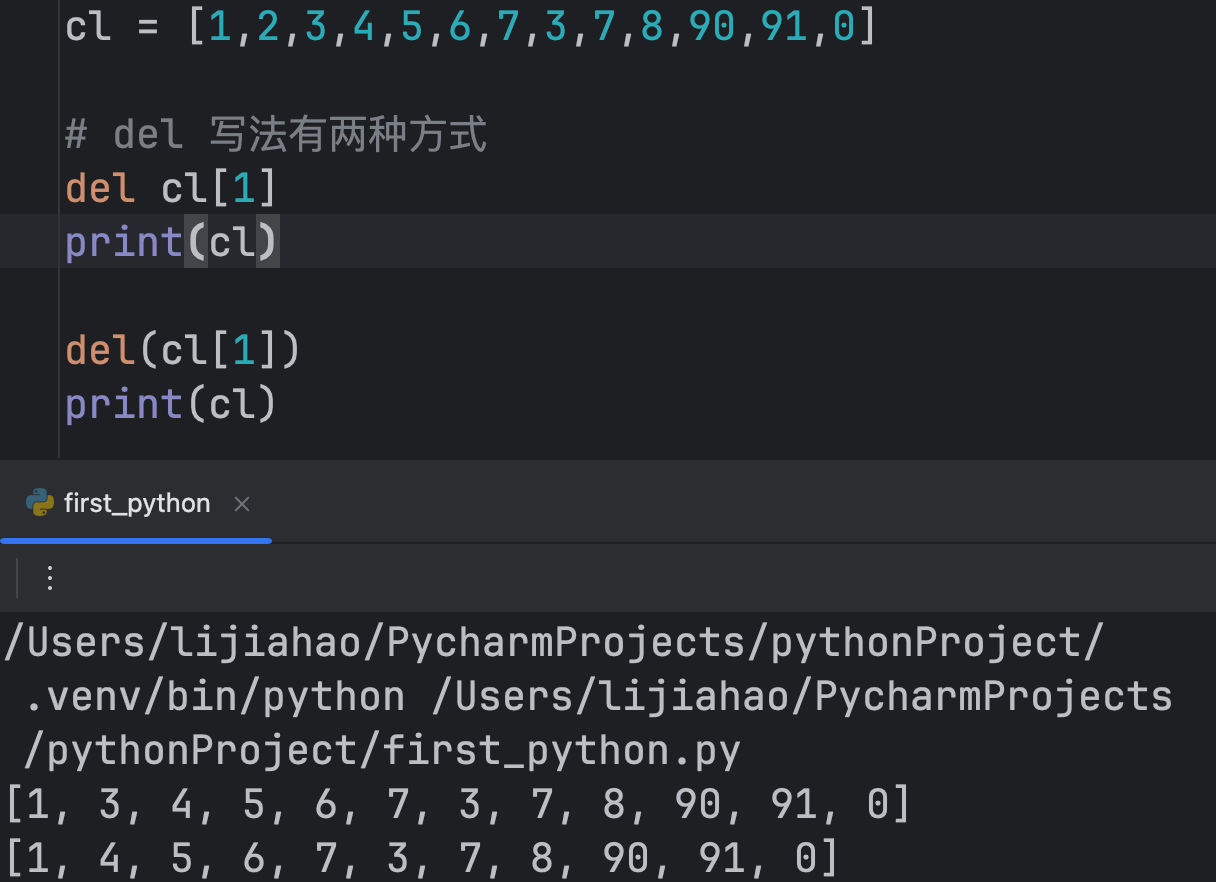
删除整个列表
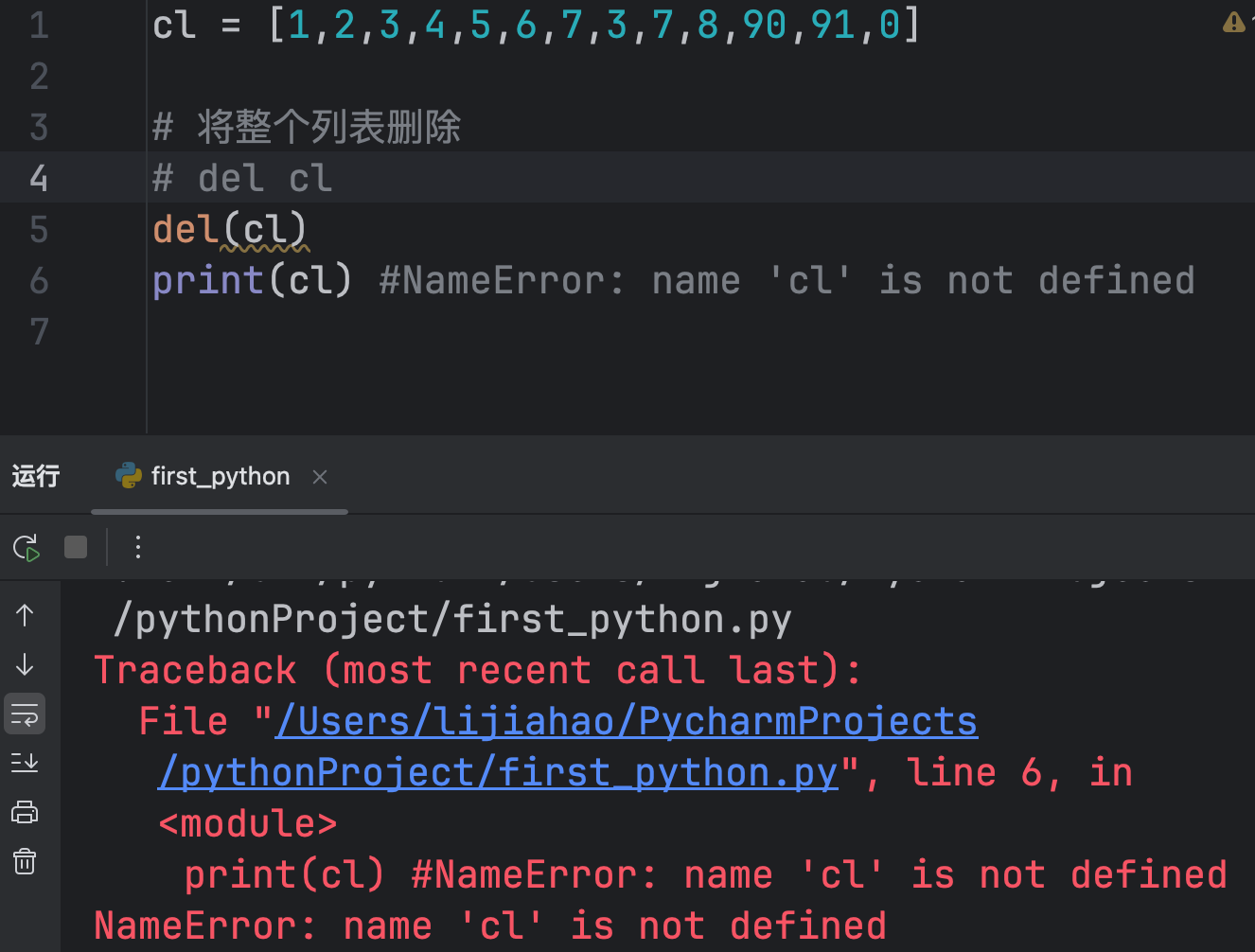
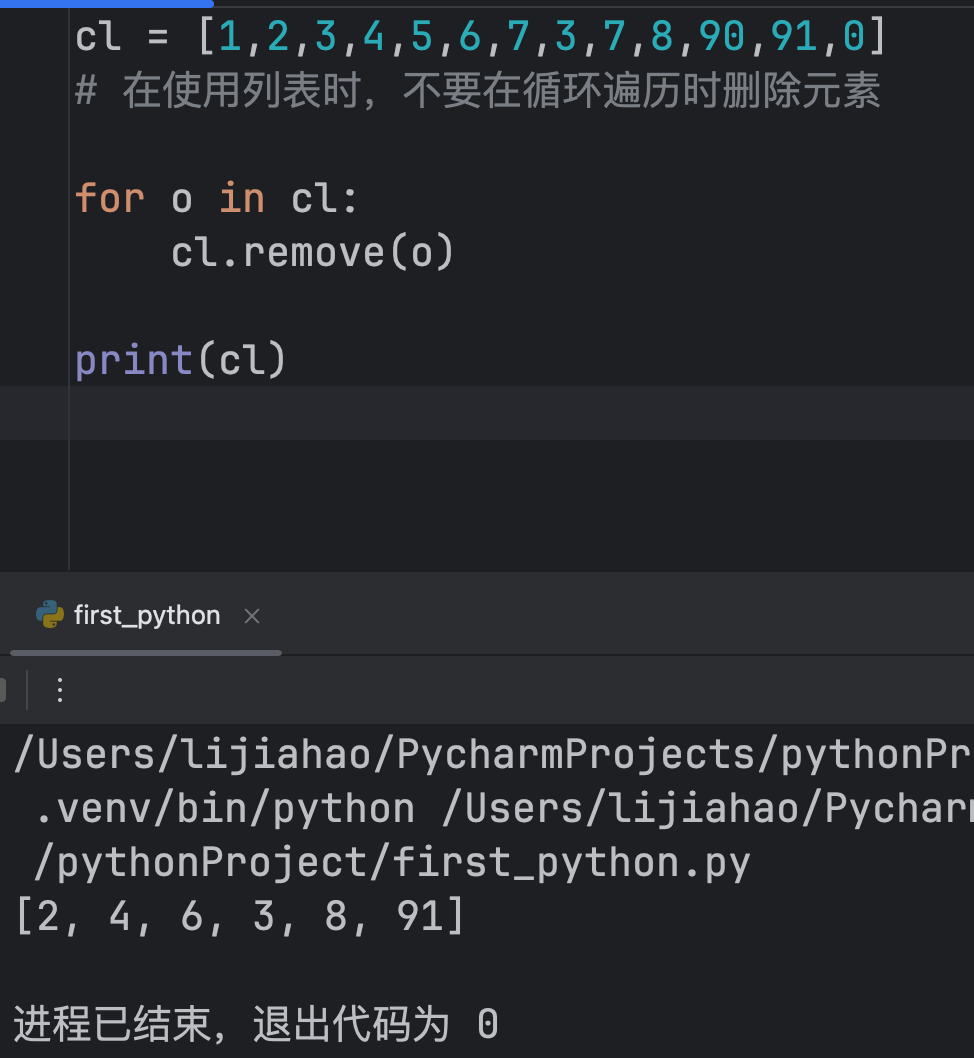
注意:在使用列表时,不要在循环遍历时删除元素
字典
字典的定义和元素访问
定义
理论,所以不可变的类型都可以做为key,
只要是可hash的的对象都可以做为key
key一般情况下使用字符串类型的数据充当
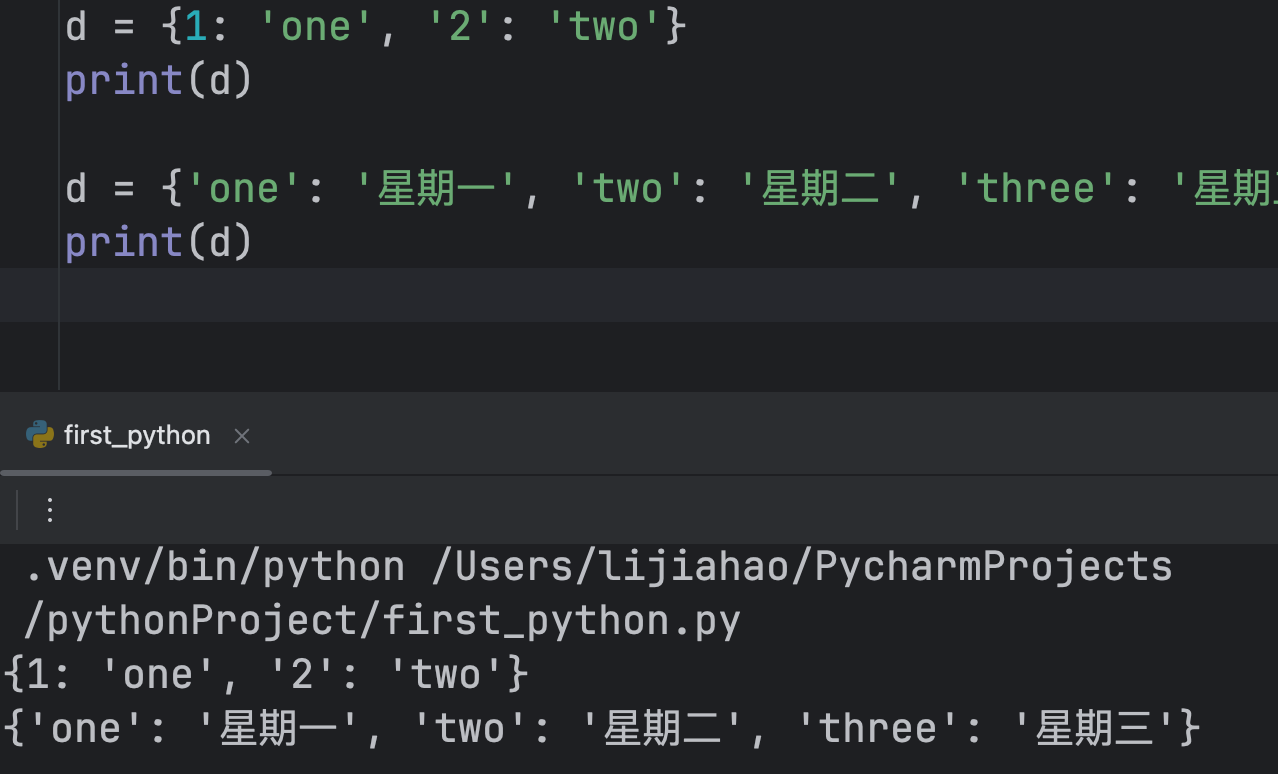
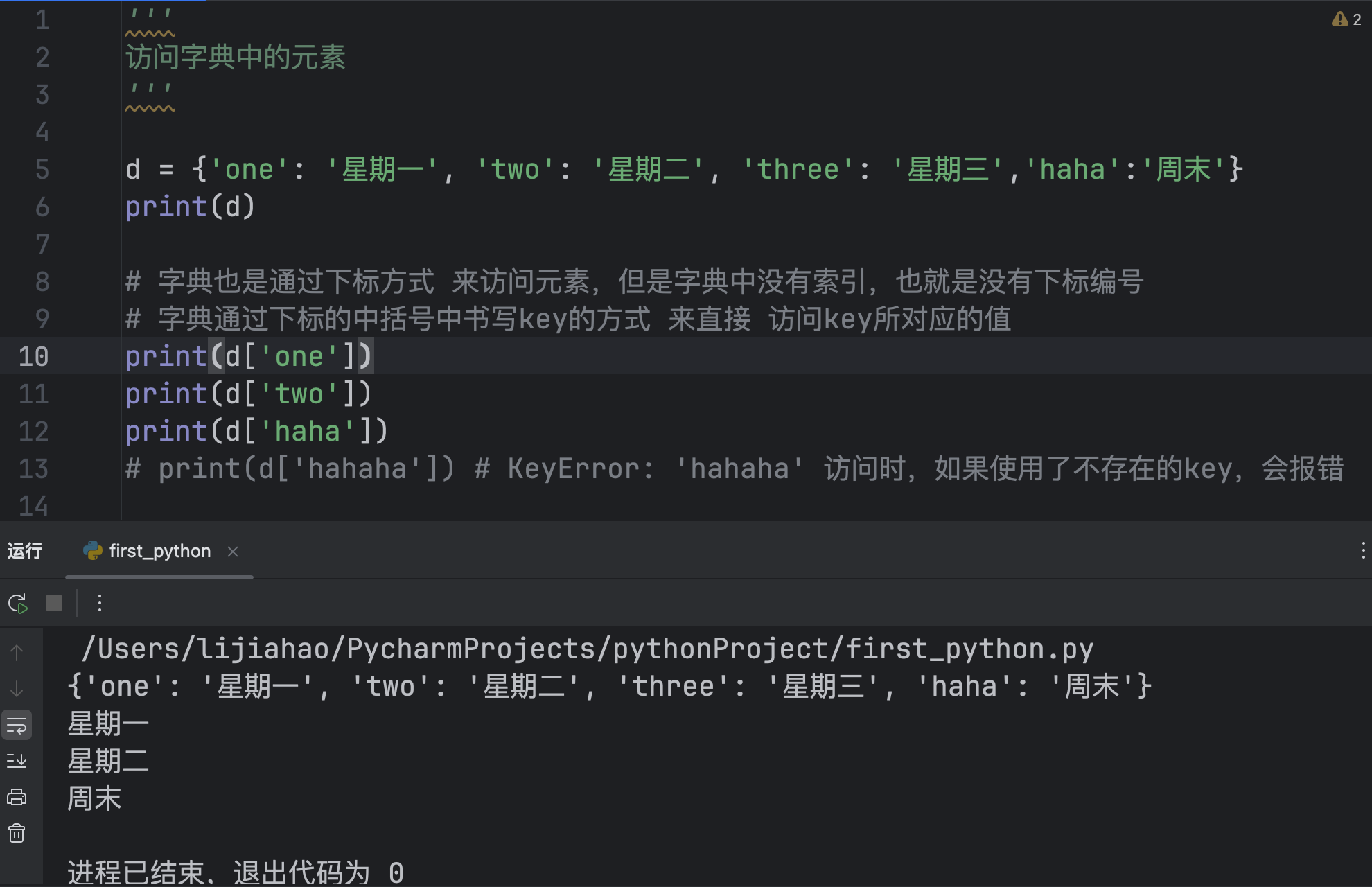
访问
字典也是通过下标方式来访问元素,但是字典中没有索引,也就是没有下标编号
字典通过下标的中括号中书写key的方式 来直接 访问key所对应的值
如果使用了不存在的key,会报错
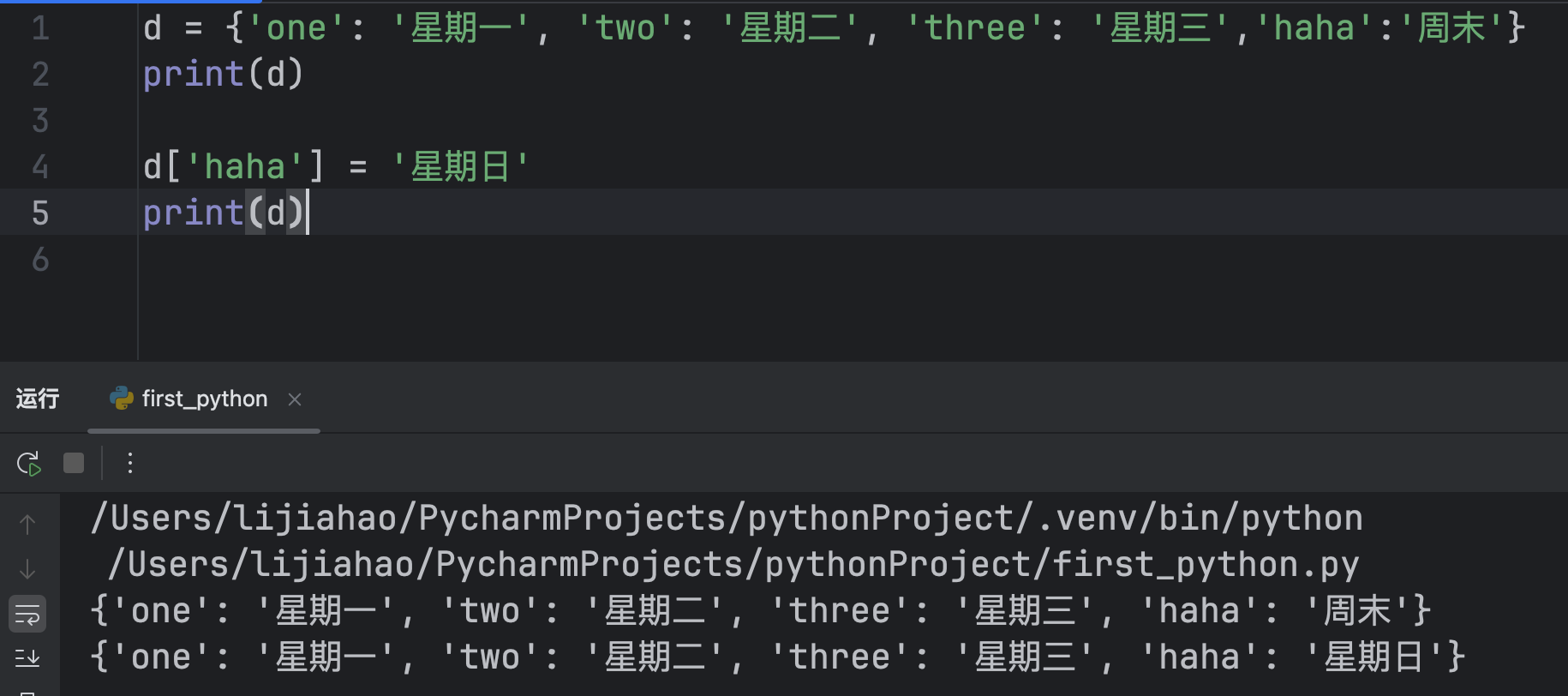
字典也是一个可变类型
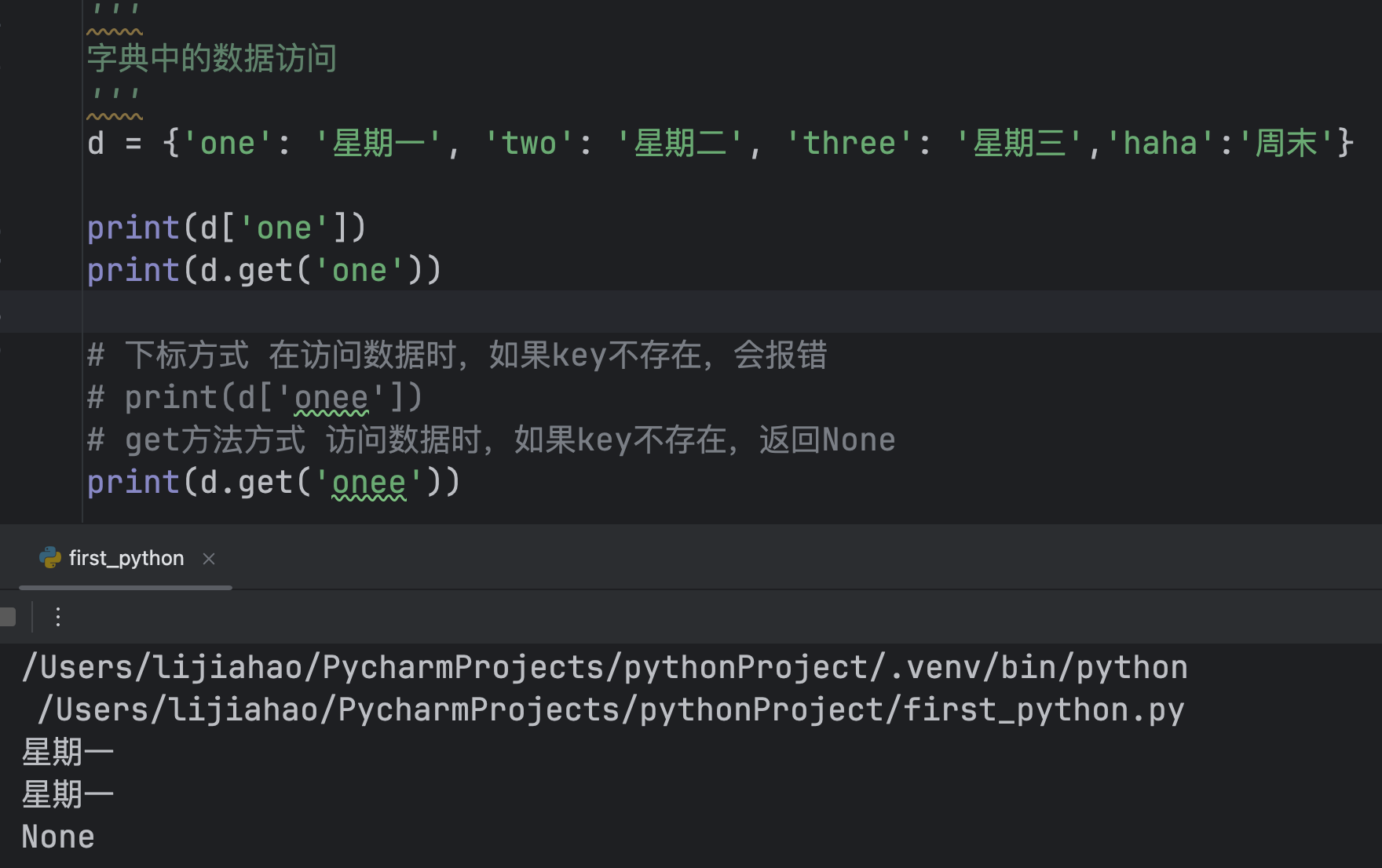
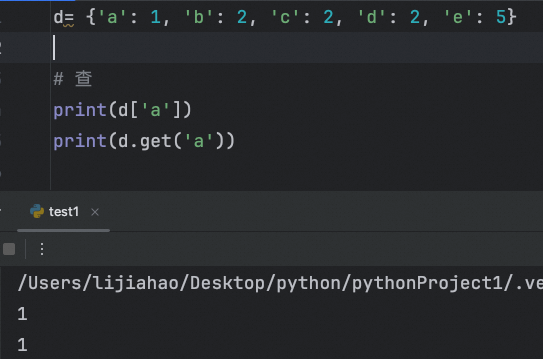
字典get()
刚才已经得知:下标方式 在访问数据时,如果key不存在,会报错
get方法方式 访问数据时,如果key不存在,返回None
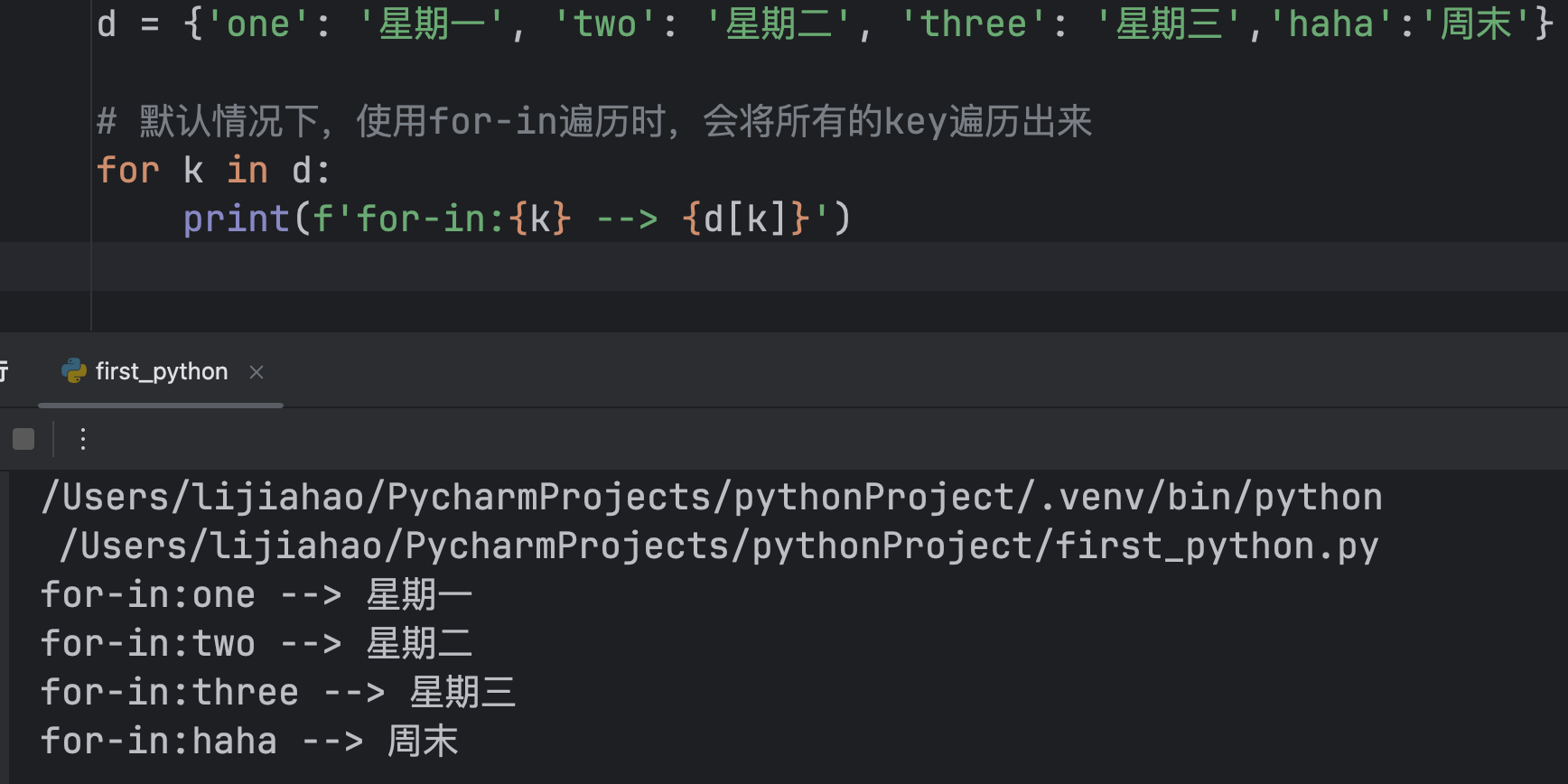
字典的遍历
方式一
# 默认情况下,使用for-in遍历时,会将所有的key遍历出来
方式二
keys()方法
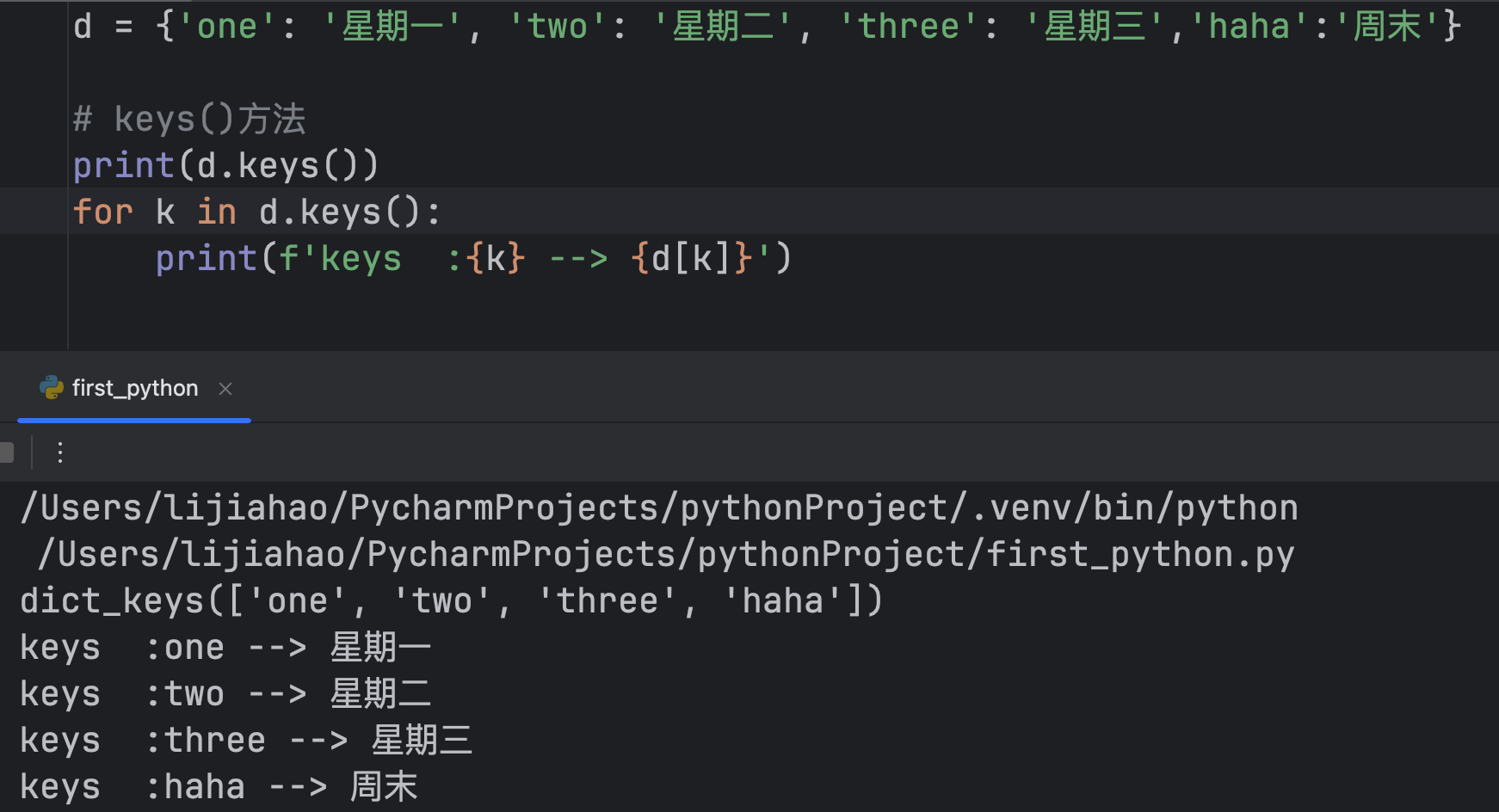
方式三
values() 方法
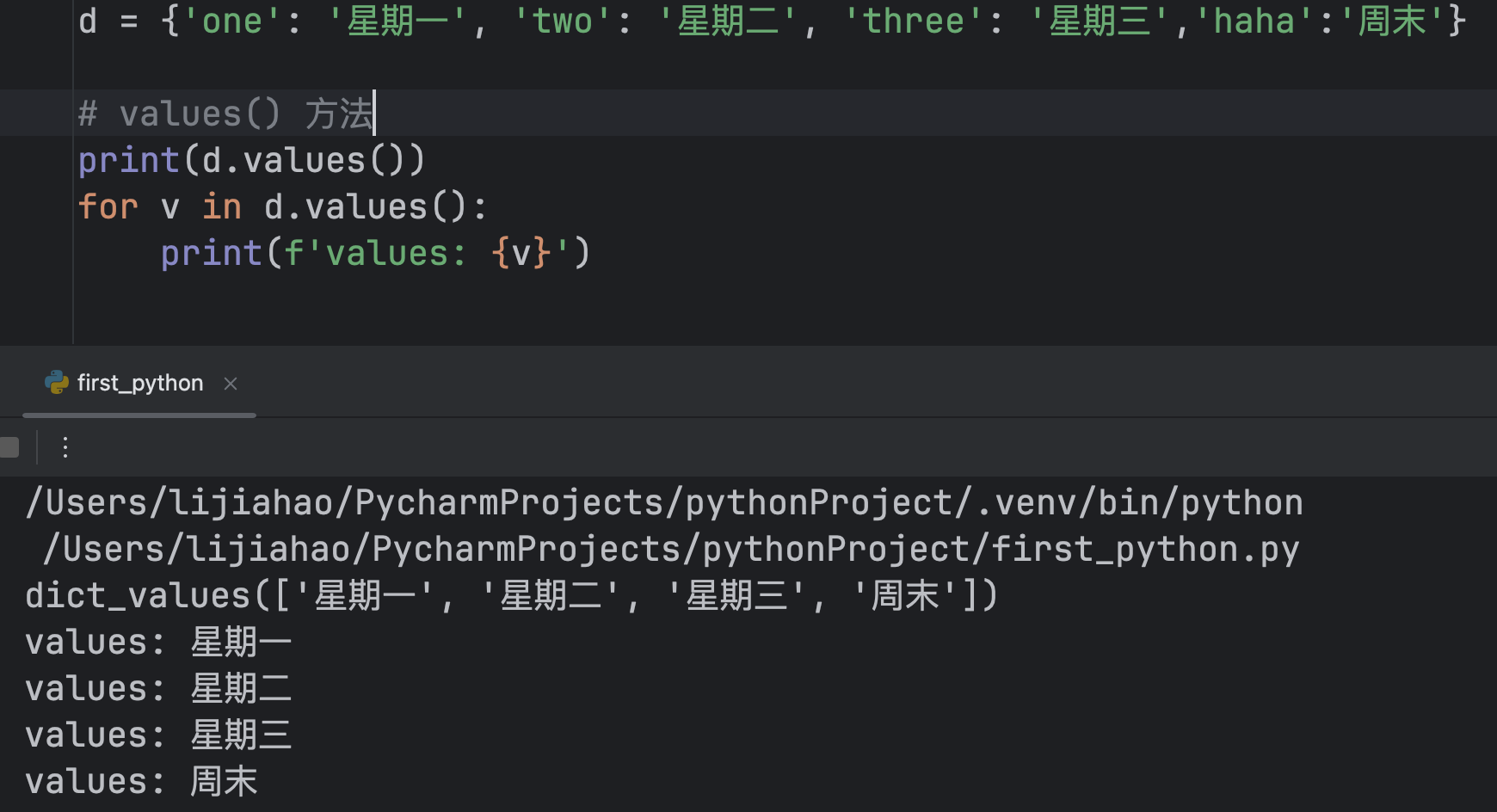
方式四
将每个元素(键值对)打包成一个元祖items()
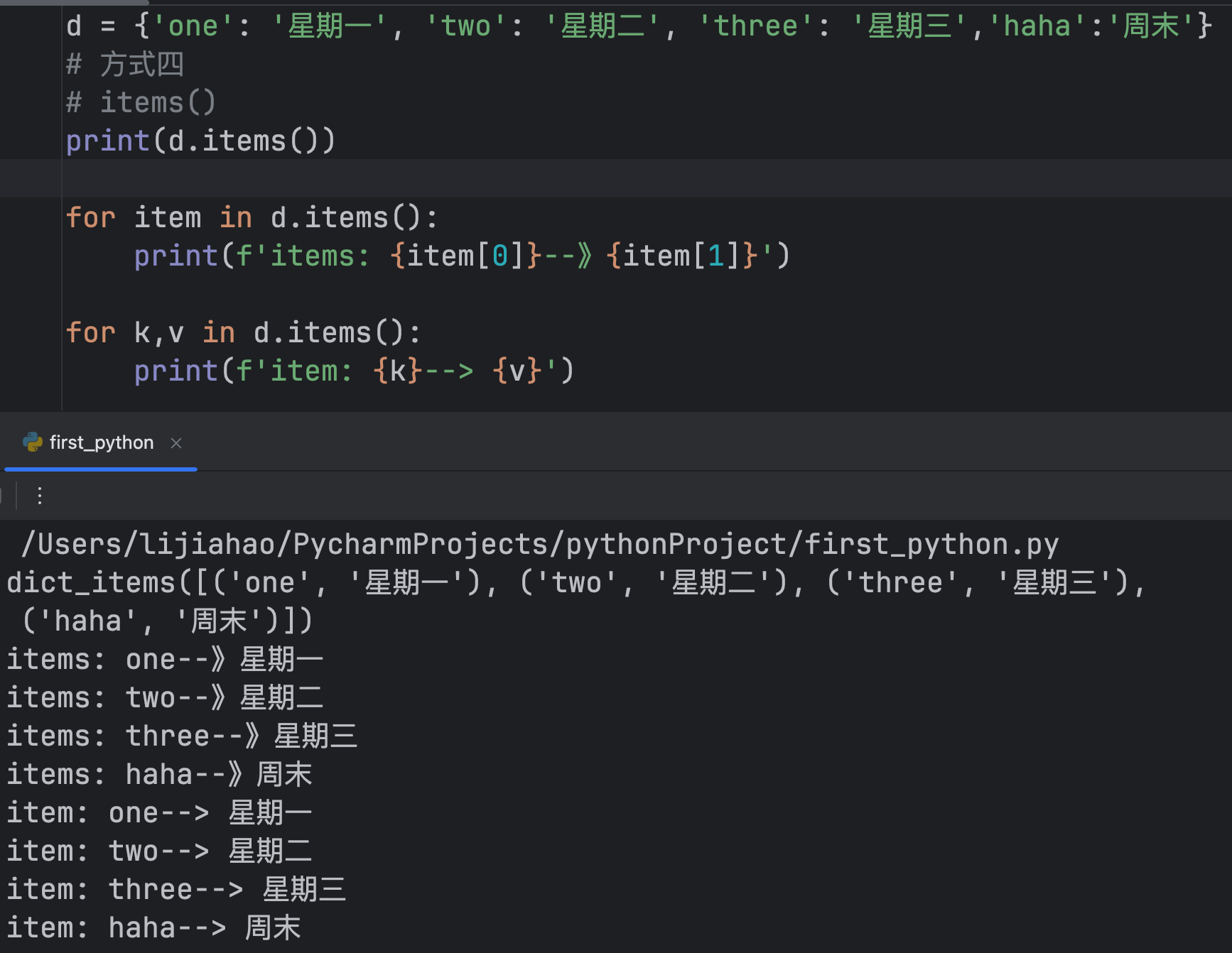
上面第二种方式涉及到了解包思想:
a,b,c,d,e = item # a,b,c,d,e = item[0],item[1],item[2],item[3],item[4]省略写法
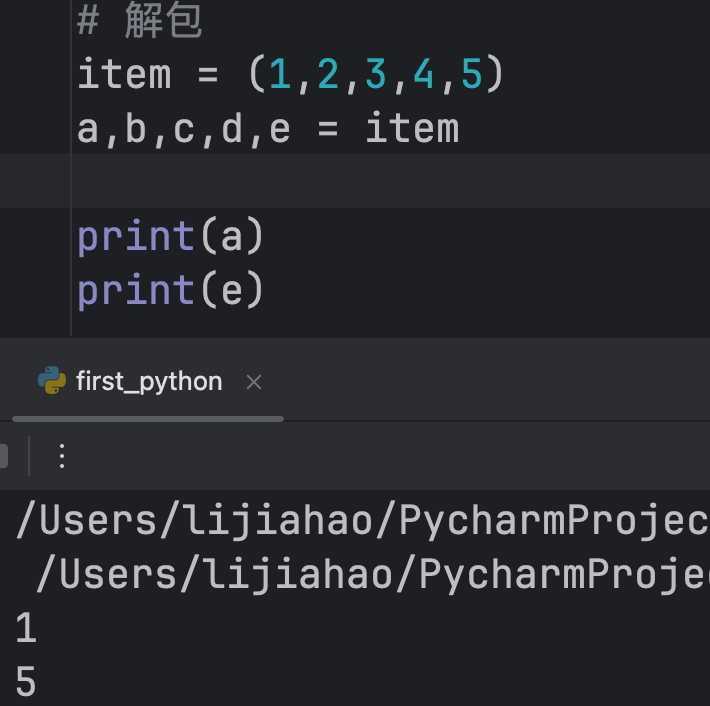
字典的常用方法:
增
如果在赋值时,使用的key在字典中不存在,那么就是向字典中添加数据
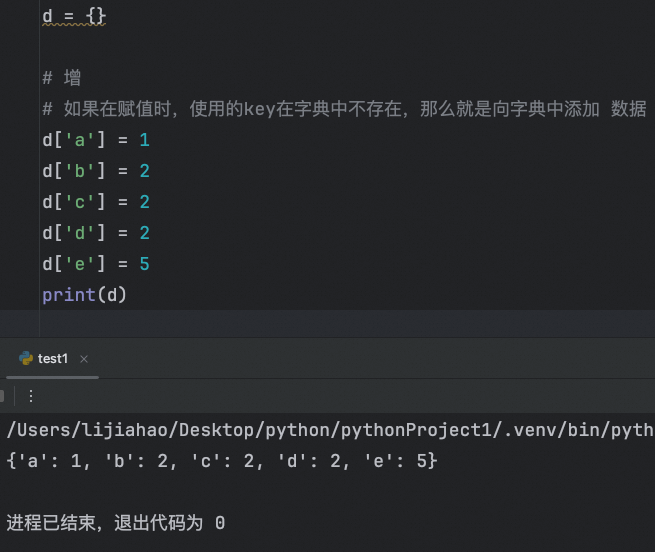
改
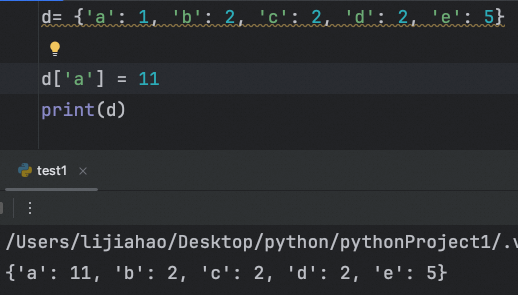
如果在赋值 时,使用的key在字典中存在,那么就修改这个key所对应的值
字典中的key 具有唯一性
如果key不存在,那么就是添加 数据,如果key存在就是修改数据
key 是不能修改的
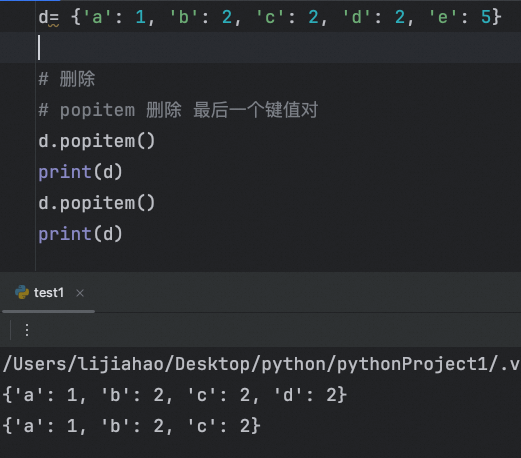
删
pop: 删除指定键的键值对,并返回该键关联的值。如果键不存在,还可以指定一个默认值返回。
popitem 删除最后一个键值对
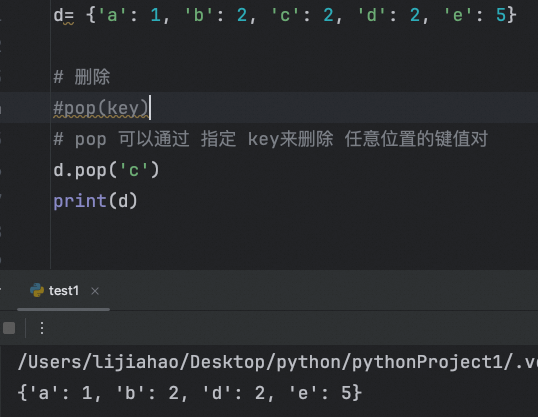
pop(key)可以通过指定key来删除任意位置的键值对
del: 只删除指定的键值对,不返回任何值。如果键不存在,会引发一个 KeyError。
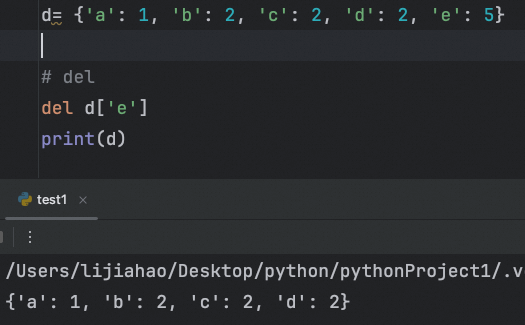
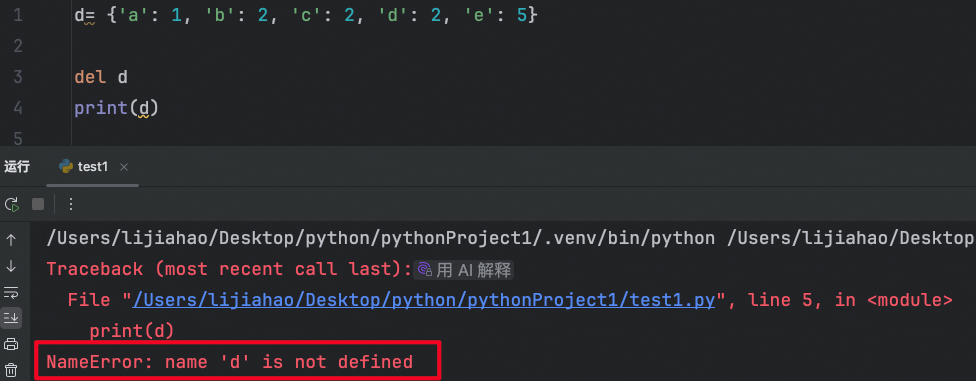
将整个字典删除
clear()清空字典中的键值对
查
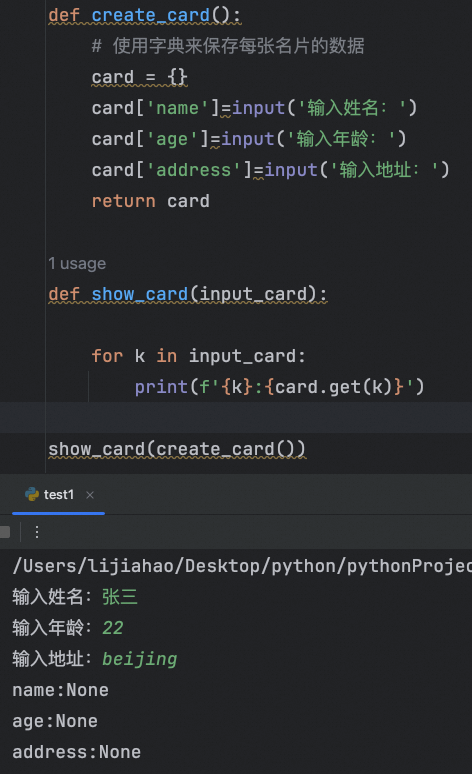
字典练习:保存名片
练习要求:
函数一: 建立名片-> 建立好的名片(需要姓名,年龄,地址信息)
函数二: 显示名片-> 接收名片信息,打印名片信息
有序字典和无序字典
在 Python 的早期版本(例如 3.7 之前),字典本身不是有序的。为了创建一个有序的字典,你可以使用 collections 模块中的 OrderedDict。OrderedDict 会记住插入键值对的顺序。
from collections import OrderedDict
# 创建一个有序字典
ordered_dict = OrderedDict()
# 添加一些键值对
ordered_dict['first'] = 1
ordered_dict['second'] = 2
ordered_dict['third'] = 3
# 打印有序字典
for key, value in ordered_dict.items():
print(key, value)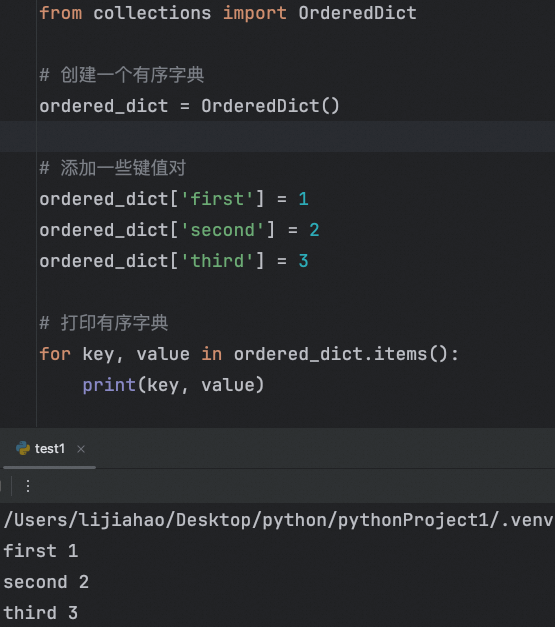
在Python中,有序字典(OrderedDict)和无序字典(普通的dict)之间主要有以下几个区别:
1、顺序性:
OrderedDict: 按照键值对插入的顺序维护顺序。这意味着当迭代OrderedDict时,元素会按照插入的顺序返回。
普通的dict: 从Python 3.7开始,标准的dict也维护插入顺序。在此之前,dict不保证顺序,虽然在Python 3.6的一些实现中也是保留了插入顺序。
2、性能:
OrderedDict: 由于需要维护顺序,性能上可能会稍微逊色于普通的dict,尤其是在插入和删除操作上。
普通的dict: 因为从3.7版本开始就维护了插入顺序,其性能通常会更为高效。
3、使用场景:
OrderedDict: 当你需要在所有Python版本中(包括老版本)都确保字典的迭代顺序与插入顺序一致时,可以使用OrderedDict。
普通的dict: 在现代Python版本中使用普通的dict通常就能满足对顺序的要求,除非你需要OrderedDict提供的额外方法。
4、额外方法:
OrderedDict: 提供了一些dict没有的方法,比如move_to_end(),它可以用来移动某个键到字典的开头或末尾。集合
在 Python 中,集合(set)是一种数据类型,它类似于列表(list)和字典(dictionary),但具有一些独特的特性。集合是一组无序且不重复的元素。它主要用于需要去重或者需要对元素进行数学集合运算的场合。
集合的特点
- 无序性:集合中的元素没有特定的顺序,因此无法通过索引进行访问。
- 去重:集合自动去除重复的元素。
- 可变性:集合本身是可变的,可以添加或删除元素,但集合中的元素必须是可哈希(hashable)的,即不可变的数据类型,如整数、字符串、元组等。
应用场景
- 去重:从列表中移除重复项,保持元素的唯一性。
- 数学运算:计算集合之间的交集、并集、差集等,特别适合统计、集合论等领域。
- 快速查询:由于集合基于哈希表实现,查询操作通常比列表更快。
集合的基本操作
创建集合
s1 = {1, 2, 3, 4}
s2 = set([3, 4, 5, 6])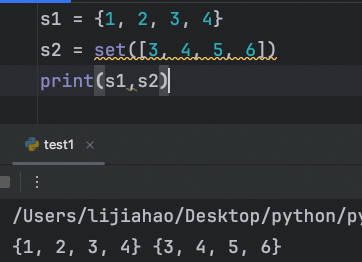
定义一个空集合
# s = {} # 这种方式 是定义一个空字典,不是集合
s = set()
print(s)
print(type(s))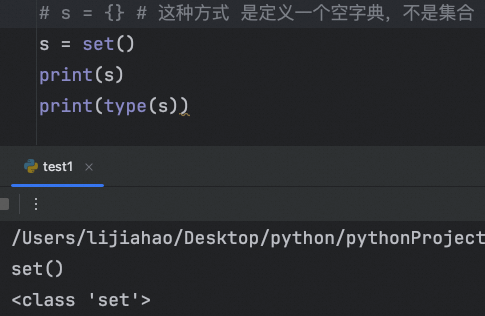
添加元素
可以使用 add() 方法向集合添加元素。
s1.add(5)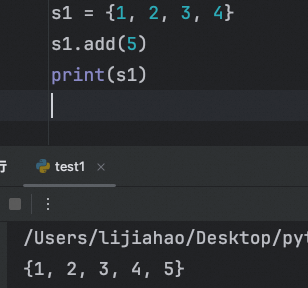
删除元素
- 使用
remove()方法删除指定的元素,若元素不存在会引发KeyError。 - 使用
discard()方法删除指定的元素,若元素不存在不会引发错误。 - 使用
pop()方法删除并返回一个任意元素,集合为空时会引发KeyError。
s1.remove(3)
s1.discard(10) # 不会抛出异常
s1.pop()集合运算
交集:set1 & set2 或 set1.intersection(set2)
并集:set1 | set2 或 set1.union(set2)
差集:set1 - set2 或 set1.difference(set2)
对称差集:set1 ^ set2 或 set1.symmetric_difference(set2)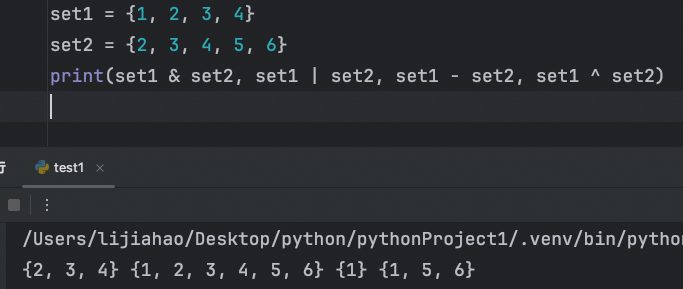
集合的去重功能
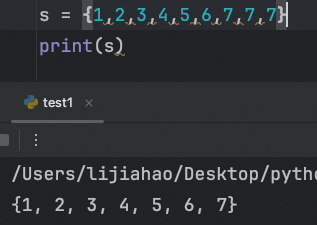
集合遍历
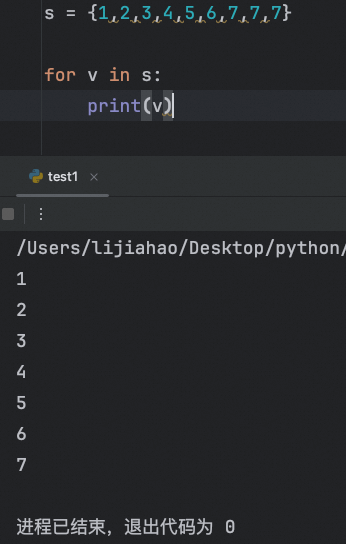
注意: 集合是不支持下标的
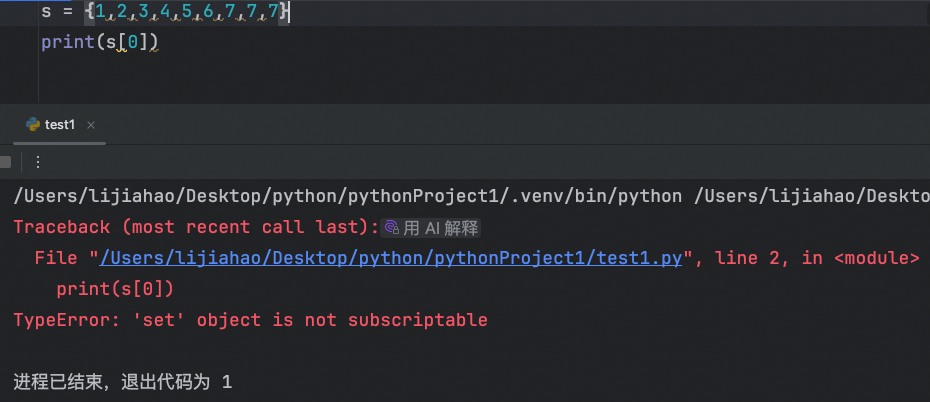
容器类型之间的类型转换
set-list-tuple三者类型间转换
字符串转列表、列表转集合(集合是无序排序)、字符串转集合
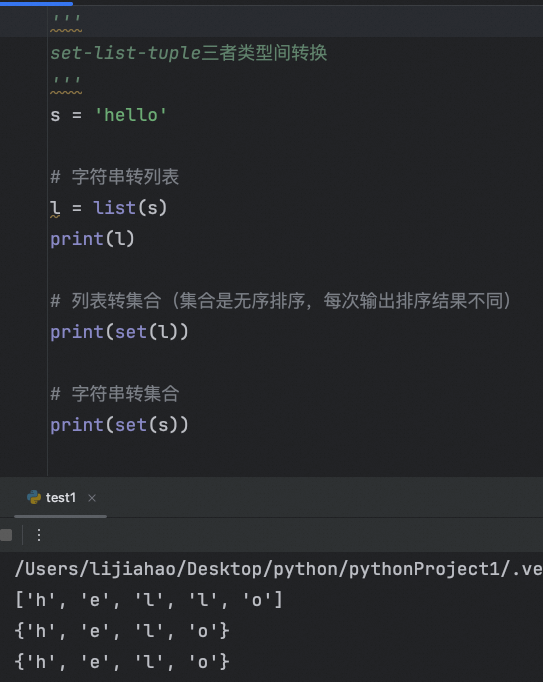
列表转字符串
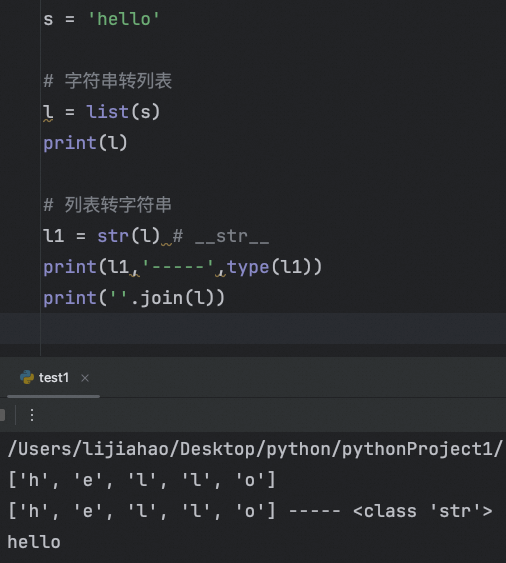
公共方法:
容器其他内置函数:
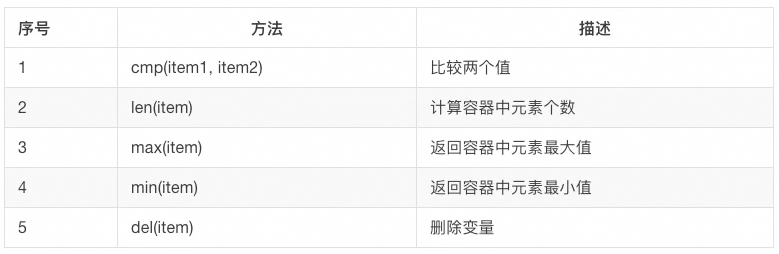
容器内置函数总结:
列表 (List)
append(x): 在列表的末尾添加元素 x。
extend(iterable): 用可迭代对象中的元素扩展列表。
insert(i, x): 在指定位置 i 插入元素 x。
remove(x): 移除列表中第一个值为 x 的元素。
pop([i]): 移除并返回指定位置 i 的元素,不指定则移除并返回最后一个元素。
clear(): 移除列表中的所有元素。
index(x[, start[, end]]): 返回指定值 x 的第一个匹配项的索引。
count(x): 返回元素 x 在列表中出现的次数。
sort(key=None, reverse=False): 对列表进行排序。
reverse(): 反转列表中的元素。
copy(): 返回列表的浅复制。
元组 (Tuple)
元组是不可变的,所以没有修改它们的方法。可以使用以下方法:
count(x): 返回元素 x 在元组中出现的次数。
index(x[, start[, end]]): 返回指定值 x 的第一个匹配项的索引。
集合 (Set)
add(elem): 向集合中添加元素 elem。
remove(elem): 移除集合中的元素 elem,如果不存在则抛出错误。
discard(elem): 移除集合中的元素 elem,如果不存在不抛出错误。
pop(): 移除并返回集合中的一个不确定的元素。
clear(): 移除集合中的所有元素。
update(*others): 用其他集合的元素更新集合。
union(*others): 返回包含集合及其他集合中所有元素的新集合。
intersection(*others): 返回集合与其他集合的交集。
difference(*others): 返回集合与其他集合的差集。
symmetric_difference(other): 返回集合与另一个集合的对称差集。
字典 (Dictionary)
clear(): 移除字典中的所有元素。
copy(): 返回字典的浅复制。
fromkeys(iterable, value=None): 创建一个新字典,键来自 iterable,值是 value。
get(key, default=None): 返回键 key 的值,不存在则返回 default。
items(): 返回字典的 (key, value) 对的视图。
keys(): 返回字典键的视图。
pop(key[, default]): 移除并返回键 key 的值,不存在则返回 default。
popitem(): 移除并返回字典中的一个 (key, value) 对,通常是最后插入的。
setdefault(key, default=None): 如果键不存在,则设置 key 的值为 default。
update([other]): 使用 other 更新字典。
values(): 返回字典值的视图。
这些方法为操作不同的容器结构提供了便捷的接口,了解和掌握这些方法可以帮助你更加高效地处理数据。列表推导式
Python 列表推导式(list comprehension)是一种简洁而优雅的方式,用于创建列表。在一行代码中,可以从一个已有的可迭代对象(如列表、元组、字符串等)生成一个新的列表。这种语法使代码看起来更清晰、更易读,也通常更具备 Pythonic 风格。
格式: 列表变量 = [表达式 for 变量 in range(10)]
new_list = [new_element for element in iterable if condition]表达式中需要使用后面的变量
例:
创建一个具有一百个数字的列表
传统方式:
c_l = []
for i in range(100):
c_l.append(i)使用列表推导式来完成列表的创建(注意,表达的变量使用要和循环中的变量一致)
c_l = [i for i in range(100)]生成一个包含 1 到 10 内的所有整数的平方的列表
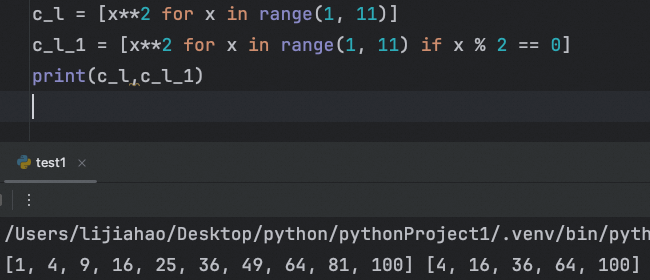
c_l = [x**2 for x in range(1, 11)]带条件的列表推导式:
如果我们只想要能被 2 整除的数的平方,可以加上条件:
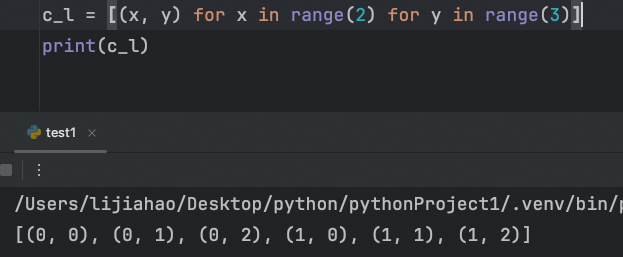
创建一个列表 ,列表中的每个元素都是具有两个值的元组
组包和拆包
组包(Packing)
组包是指将多个值组合成一个单一的元组(或其他集合类型)。这通常在需要将多个元素作为一个整体进行处理时很有用。例如,当你用逗号分隔多个值时,Python 会自动将它们打包到一个元组中。
# 例子:组包
a = 1, 2, 3 # 这实际上是 (1, 2, 3)
print(a) # 输出: (1, 2, 3)
# 也可以显式地用括号
b = (4, 5, 6)
print(b) # 输出: (4, 5, 6)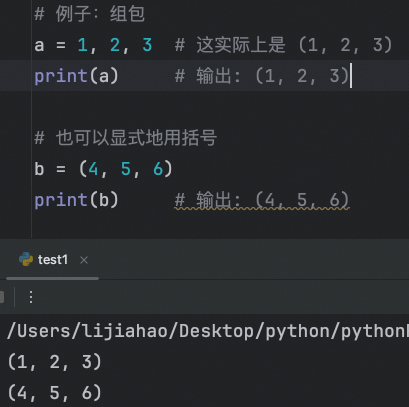
拆包(Unpacking)
拆包是指把一个元组或列表中包含的多个值分配给多个变量。这在需要将集合的元素进行单独处理时非常有用。在拆包中,变量的数量必须和被拆包的集合中元素的数量相同(如果变量数量不够,报错为ValueError: too many values to unpack,如果变量数量过多,报错 ValueError: not enough values to unpack)。
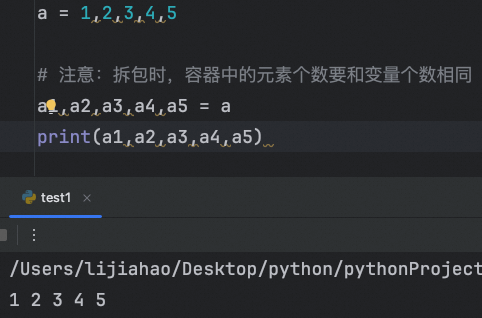
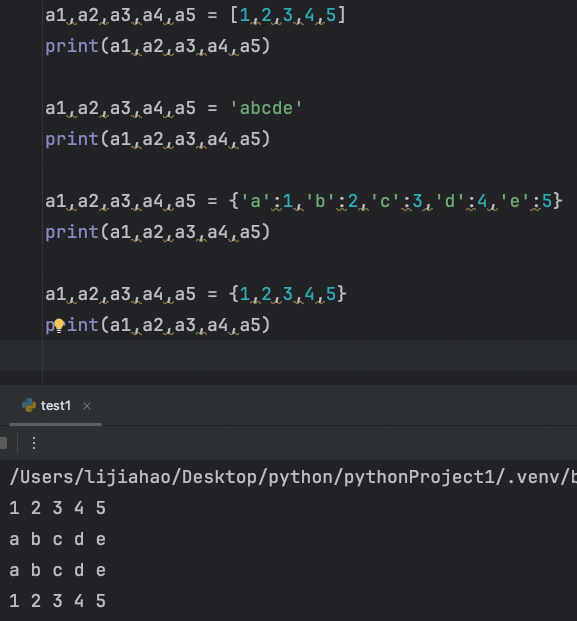
拆包不仅限于元组,对列表、集合等其他可迭代对象也可以进行。
特殊用法
在拆包时,你可以使用星号(*)来捕获多余的值。如果在拆包时,不知道具体元素个数或者只关心其中几个元素,可以使用星号表达式:
# 使用星号解包
numbers = (1, 2, 3, 4, 5)
head, *middle, tail = numbers
print(head) # 输出: 1
print(middle) # 输出: [2, 3, 4]
print(tail) # 输出: 5这种星号表达式在处理不确定长度的可迭代对象时尤其有用。
发布者:LJH,转发请注明出处:https://www.ljh.cool/41639.html