
并发和并行
在 Python 中,“并发(Concurrency)”和“并行(Parallelism)”是两个相关但不同的概念,它们主要区别在于任务执行的方式和底层机制。
1. 并发(Concurrency)
- 定义:多个任务在同一个时间段内交替进行,任务之间通过快速切换 CPU 时间片看起来“同时”执行,但在某个时刻 CPU 只执行一个任务。
- 实现方式:线程(threading)、协程(asyncio)、事件循环。
- 特点:
- 适合 I/O 密集型任务(如网络请求、文件读写),因为线程或协程可以在等待 I/O 的时候让出控制权,去处理别的任务。
- 任务不是同时真正运行,而是交替执行。
- 示例:
- 多线程同时处理多个网络请求。
asyncio中通过协程实现高效的异步 I/O。
2. 并行(Parallelism)
- 定义:多个任务真正同时执行,任务在物理上的多个 CPU 核心上并行运行。
- 实现方式:多进程(multiprocessing)、多线程在多核 CPU 上(虽然 Python 由于 GIL 限制,线程并行受限,适合 I/O 密集,计算密集建议用多进程)。
- 特点:
- 适合 CPU 密集型任务(如大规模计算、图像处理)。
- 任务同时执行,提升计算效率。
- 示例:
- 使用
multiprocessing在多个 CPU 核心上并行计算。 - Python 线程受 GIL 限制无法实现真正的并行计算。
- 使用
3. Python 中的特殊点:GIL(全局解释器锁)
- Python 的主流解释器 CPython 有 GIL,导致同一时刻只有一个线程能执行 Python 字节码(解释执行)。
- 这意味着 Python 多线程对于 CPU 密集型任务不能实现真正并行,只适合 I/O 密集型并发。
- 需要真正并行计算时,通常使用多进程(
multiprocessing模块),因为每个进程有独立的 Python 解释器和内存空间,不受 GIL 限制。
总结:
| 维度 | 并发(Concurrency) | 并行(Parallelism) |
|---|---|---|
| 执行方式 | 任务交替执行(时间片轮转) | 任务真正同时执行(多核同时运行) |
| 适用场景 | I/O 密集型 | CPU 密集型 |
| Python实现 | 线程(threading)、协程(asyncio) | 多进程(multiprocessing)、部分扩展库支持 |
| 受限因素 | CPU 单核,GIL 限制线程并行执行 | 需要多核CPU和多进程支持 |
| 示例 | 多线程处理多个文件下载 | 多进程图像处理、科学计算 |
进程介绍
python 中如何创建一个单任务程序?
在 Python 中创建一个单任务程序是非常简单的。单任务程序意味着程序一次只能执行一个任务,没有并发或并行处理。在这种情况下,程序会从上到下顺序执行代码。下面是一个简单的示例,说明如何创建一个单任务程序:
def greet_user():
name = input("请输入你的名字: ")
print(f"你好, {name}!")
def calculate_sum():
num1 = int(input("请输入第一个数字: "))
num2 = int(input("请输入第二个数字: "))
print(f"两个数字的和是: {num1 + num2}")
def main():
print("欢迎来到单任务程序!")
greet_user()
calculate_sum()
print("程序结束。")
if __name__ == "__main__":
main()
在这个示例中,程序按顺序执行以下任务:
- 打印欢迎信息。
- 提示用户输入名字并打印问候语。
- 提示用户输入两个数字并计算它们的和。
- 打印结束信息。
每个步骤按顺序执行,只有当前任务完成后才会继续下一个任务。这就是典型的单任务程序行为。
python 中如何创建多任务程序?
使用多线程
使用 threading 模块可以在 Python 中创建多线程程序:
import threading
import time
def task1():
for i in range(5):
print(f"任务1 - 计数: {i}")
time.sleep(1)
def task2():
for i in range(5):
print(f"任务2 - 计数: {i}")
time.sleep(1)
def main():
# 创建线程
thread1 = threading.Thread(target=task1)
thread2 = threading.Thread(target=task2)
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
print("所有任务完成。")
if __name__ == "__main__":
main()

使用多进程
使用 multiprocessing 模块可以在 Python 中创建多进程程序:
import multiprocessing
import time
def task1():
for i in range(5):
print(f"任务1 - 计数: {i}")
time.sleep(1)
def task2():
for i in range(5):
print(f"任务2 - 计数: {i}")
time.sleep(1)
def main():
# 创建进程
process1 = multiprocessing.Process(target=task1)
process2 = multiprocessing.Process(target=task2)
# 启动进程
process1.start()
process2.start()
# 等待进程完成
process1.join()
process2.join()
print("所有任务完成。")
if __name__ == "__main__":
main()
- 多线程适合 I/O 密集型任务,因为 Python 的全局解释锁 (GIL) 限制了线程的并行执行。多线程允许任务在等待 I/O 操作时处理其他任务。
- 多进程更适合 CPU 密集型任务,因为每个进程在其自己的 Python 解释器实例中运行,不受 GIL 的限制。这使得多个进程可以真正地并行执行。
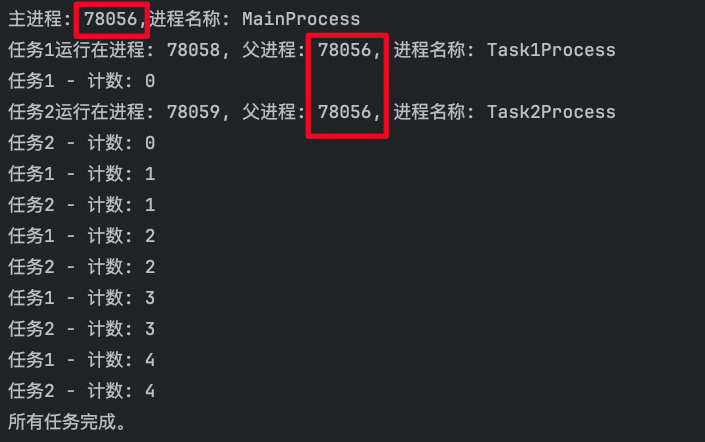
如何获取进程 ID 和进程对象名称?
使用多进程这段代码中,共有三个进程:
- 主进程:负责运行
main()函数并管理子进程。 - 子进程1:运行
task1()函数。 - 子进程2:运行
task2()函数。
1、获取进程对象 id:
- 在 Python 的
multiprocessing模块中,你可以通过os模块来获取一个进程的父进程 ID。具体来说,可以使用os.getppid()函数来获取当前进程的父进程 ID。这在子进程中调用时非常有用,它可以用来识别哪个父进程生成了当前子进程。
2、获取进程对象名称:
multiprocessing.current_process(): 在子进程中调用此函数可以获得当前进程对象,从而可以访问它的属性,包括名称。- 设置进程名称: 在创建
multiprocessing.Process对象时,你可以通过name参数来设置进程的名字,例如name='Task1Process'。 - 打印进程名称: 通过
current_process.name可以获取并打印当前进程的名称。
import multiprocessing
import time
import os
def task1():
current_process = multiprocessing.current_process()
print(f"任务1运行在进程: {os.getpid()}, 父进程: {os.getppid()}, 进程名称: {current_process.name}")
for i in range(5):
print(f"任务1 - 计数: {i}")
time.sleep(1)
def task2():
current_process = multiprocessing.current_process()
print(f"任务2运行在进程: {os.getpid()}, 父进程: {os.getppid()}, 进程名称: {current_process.name}")
for i in range(5):
print(f"任务2 - 计数: {i}")
time.sleep(1)
def main():
print(f"主进程: {os.getpid()}")
# 创建进程
process1 = multiprocessing.Process(target=task1, name='Task1Process')
process2 = multiprocessing.Process(target=task2, name='Task2Process')
# 启动进程
process1.start()
process2.start()
# 等待进程完成
process1.join()
process2.join()
print("所有任务完成。")
if __name__ == "__main__":
main()
进程传参
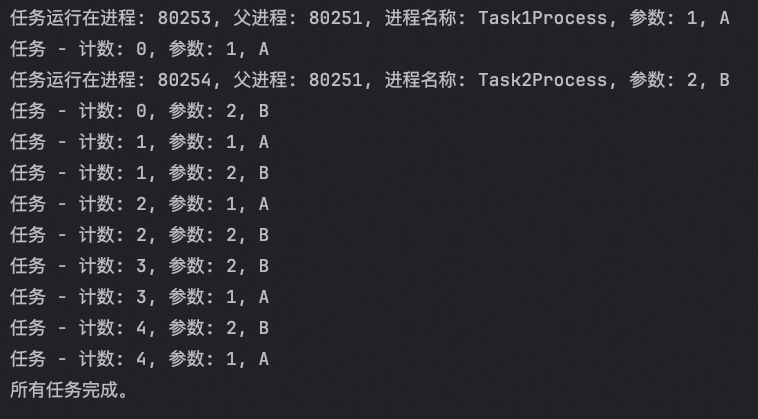
前面我们使用进程执行的任务是没有参数的,假如我们使用进程执行的任务带有参数,如何给函数传参呢?
在 Python 的 multiprocessing 模块中,传递参数给进程中的目标函数可以通过在创建 Process 对象时使用 args 或 kwargs 参数。这两种方法允许你以不同的方式传递参数。以下是如何实现这两种方法的示例:
使用 args 传递位置参数
如果你的函数需要接受位置参数,你可以通过 args 参数来传递一个元组,这个元组中的元素会被顺序传递给目标函数。
import multiprocessing
import time
import os
def task(parameter1, parameter2):
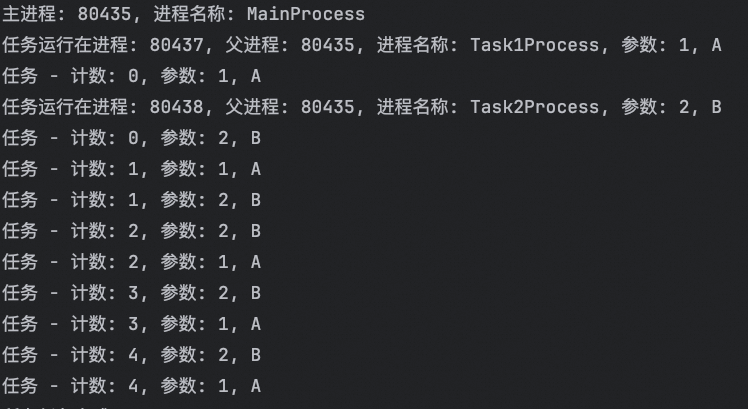
current_process = multiprocessing.current_process()
print(f"任务运行在进程: {os.getpid()}, 父进程: {os.getppid()}, 进程名称: {current_process.name}, 参数: {parameter1}, {parameter2}")
for i in range(5):
print(f"任务 - 计数: {i}, 参数: {parameter1}, {parameter2}")
time.sleep(1)
def main():
current_process = multiprocessing.current_process()
print(f"主进程: {os.getpid()}, 进程名称: {current_process.name}")
# 创建进程,传递参数
process1 = multiprocessing.Process(target=task, args=(1, 'A'), name='Task1Process')
process2 = multiprocessing.Process(target=task, args=(2, 'B'), name='Task2Process')
# 启动进程
process1.start()
process2.start()
# 等待进程完成
process1.join()
process2.join()
print("所有任务完成。")
if __name__ == "__main__":
main()
使用 kwargs 传递关键字参数
如果你的函数需要接受关键字参数,你可以通过 kwargs 参数来传递一个字典,将其参数名和值对应。
import multiprocessing
import time
import os
def task(parameter1, parameter2):
current_process = multiprocessing.current_process()
print(f"任务运行在进程: {os.getpid()}, 父进程: {os.getppid()}, 进程名称: {current_process.name}, 参数: {parameter1}, {parameter2}")
for i in range(5):
print(f"任务 - 计数: {i}, 参数: {parameter1}, {parameter2}")
time.sleep(1)
def main():
current_process = multiprocessing.current_process()
print(f"主进程: {os.getpid()}, 进程名称: {current_process.name}")
# 创建进程,传递参数
process1 = multiprocessing.Process(target=task, kwargs={'parameter1': 1, 'parameter2': 'A'}, name='Task1Process')
process2 = multiprocessing.Process(target=task, kwargs={'parameter1': 2, 'parameter2': 'B'}, name='Task2Process')
# 启动进程
process1.start()
process2.start()
# 等待进程完成
process1.join()
process2.join()
print("所有任务完成。")
if __name__ == "__main__":
main()
总结
- 使用
args: 适合传递位置参数,传递的元组其元素按照顺序对应到函数参数。 - 使用
kwargs: 适合传递关键字参数,传递的字典其键值对可以在函数中被识别和使用。
为了更快适应这种传参,下面通过一个较为复杂的传参来举例:
import multiprocessing
import time
import os
def complex_task(num, text, data_list, data_dict, option1=None, option2=None):
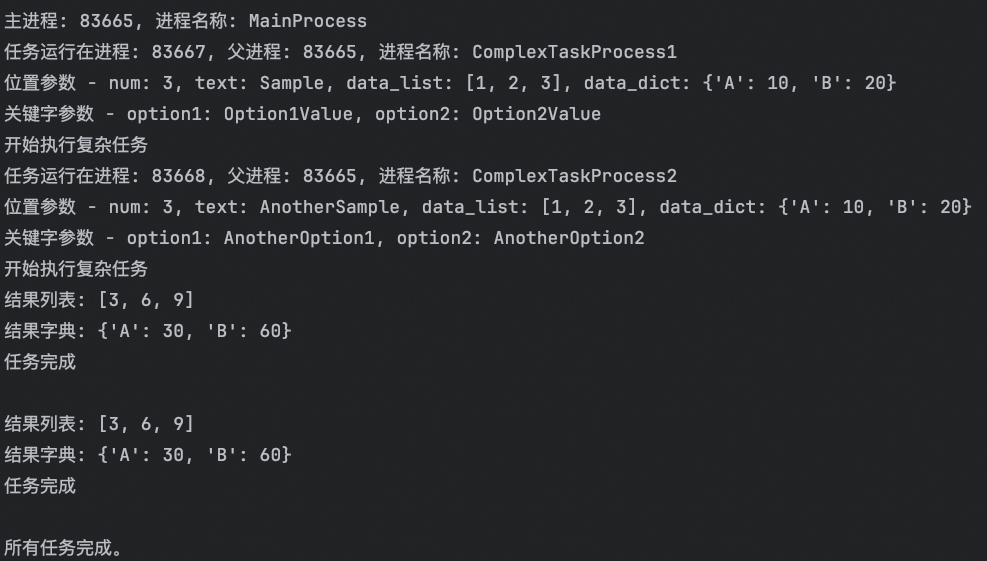
current_process = multiprocessing.current_process()
print(f"任务运行在进程: {os.getpid()}, 父进程: {os.getppid()}, 进程名称: {current_process.name}")
print(f"位置参数 - num: {num}, text: {text}, data_list: {data_list}, data_dict: {data_dict}")
print(f"关键字参数 - option1: {option1}, option2: {option2}")
# 模拟复杂的计算或操作
print("开始执行复杂任务")
time.sleep(1)
result_list = [item * num for item in data_list]
result_dict = {key: value * num for key, value in data_dict.items()}
print(f"结果列表: {result_list}")
print(f"结果字典: {result_dict}")
print("任务完成\n")
def main():
current_process = multiprocessing.current_process()
print(f"主进程: {os.getpid()}, 进程名称: {current_process.name}")
# 定义参数
num = 3
text = "Sample"
list_data = [1, 2, 3]
dict_data = {'A': 10, 'B': 20}
# 创建进程,传递复杂参数
process1 = multiprocessing.Process(
target=complex_task,
args=(num, text, list_data, dict_data),
kwargs={'option1': 'Option1Value', 'option2': 'Option2Value'},
name='ComplexTaskProcess1'
)
# 创建第二个进程以不同参数进行区分
process2 = multiprocessing.Process(
target=complex_task,
args=(num, "AnotherSample", list_data, dict_data),
kwargs={'option1': 'AnotherOption1', 'option2': 'AnotherOption2'},
name='ComplexTaskProcess2'
)
# 启动进程
process1.start()
process2.start()
# 等待进程完成
process1.join()
process2.join()
print("所有任务完成。")
if __name__ == "__main__":
main()
complex_task 函数:
- 接受多个普通参数和关键字参数,模拟执行一些复杂操作。
- 打印当前进程的信息,包括进程 ID、父进程 ID、进程名称。
- 打印函数接收到的位置参数和关键字参数。
- 模拟复杂操作(以睡眠时间代表执行延迟)。
- 使用列表推导式和字典推导式对传入数据进行处理,将每个数据值乘以
num参数,生成新的列表和字典结果。 - 打印计算结果,表明任务完成。
进程的其他特性:
进程间不共享全局变量
在 Python 中,进程间是不共享全局变量的。这是因为 multiprocessing 模块创建的每一个进程都是独立的,拥有自己的内存空间。每个进程运行一份代码的副本,并独立于其他进程管理自己的变量和状态。
以下是一个示例,演示不同进程对全局变量的修改不会影响其他进程中的全局变量:
import multiprocessing
import time
# 定义一个全局变量
global_variable = 0
def worker_1():
global global_variable
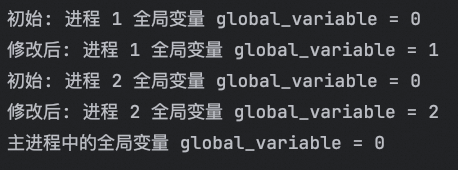
print(f"初始: 进程 1 全局变量 global_variable = {global_variable}")
# 修改全局变量
global_variable = 1
time.sleep(1)
print(f"修改后: 进程 1 全局变量 global_variable = {global_variable}")
def worker_2():
global global_variable
print(f"初始: 进程 2 全局变量 global_variable = {global_variable}")
# 修改全局变量
global_variable = 2
time.sleep(1)
print(f"修改后: 进程 2 全局变量 global_variable = {global_variable}")
def main():
# 创建两个进程
p1 = multiprocessing.Process(target=worker_1)
p2 = multiprocessing.Process(target=worker_2)
p1.start()
p1.join()
# p2等待p1执行完成后再初始化和执行
p2.start()
p2.join()
# 打印主进程中的全局变量
print(f"主进程中的全局变量 global_variable = {global_variable}")
if __name__ == "__main__":
main()
代码解释:
- 全局变量
global_variable: 在主进程中初始化为0。 worker_1()和worker_2():- 每个进程函数都尝试获取和修改全局变量
global_variable。 - 因为 Python 的多进程特性,每个进程在运行时拥有自己独立的
global_variable,因此修改不会影响其他进程。
- 每个进程函数都尝试获取和修改全局变量
- 结果:
- 你会发现虽然p1进程修改了
global_variable,但这些修改只在p1进程的作用域内生效。 - p2 执行再 p1 之后,但global_variable依然获取的值为0
- 最后打印主进程的
global_variable仍然是初始值0。
- 你会发现虽然p1进程修改了
为了证明Python 的 multiprocessing 模块在每个新进程启动时,都会为其分配独立的内存空间。可以通过比较进程内存空间的 ID 来展示这一点。下面的代码演示了如何通过获取对象的内存地址来展示在不同进程中的全局变量拥有不同的内存 ID,从而证明各个进程是独立的。
import multiprocessing
import ctypes
# 定义一个全局变量
global_variable = ctypes.c_int(0) # 使用 ctypes 包装变量以正确获取其内存地址
def worker_1():
global global_variable
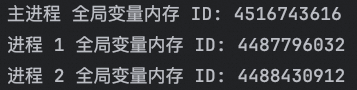
print(f"进程 1 全局变量内存 ID: {id(global_variable)}")
global_variable.value = 1
def worker_2():
global global_variable
print(f"进程 2 全局变量内存 ID: {id(global_variable)}")
global_variable.value = 2
def main():
# 打印主进程中的全局变量的内存 ID
print(f"主进程 全局变量内存 ID: {id(global_variable)}")
# 创建两个进程
p1 = multiprocessing.Process(target=worker_1)
p2 = multiprocessing.Process(target=worker_2)
# 启动进程
p1.start()
p2.start()
# 等待进程完成
p1.join()
p2.join()
if __name__ == "__main__":
main()
在多进程环境中,进程之间是不共享内存空间的,也就是说全局变量在不同进程中各自独立。如果需要在进程间共享状态或数据,可以使用 multiprocessing 提供的其他同步机制和数据共享机制,比如 Queue、Pipe、Manager 或 Value 和 Array 等。
主进程会等待所有的子进程执行结束再结束
主进程默认情况下不会主动等待子进程完成。除非显式调用join()方法或使用其他同步机制,否则主进程会继续执行,可能会在子进程还在运行时结束。在没有使用join()或其他机制时,如果子进程不是守护进程,它们会继续运行直到完成。这可以导致输出看起来混合,因为子进程可能会在主进程结束后继续工作。
下面是一个简单的代码示例,用来展示主进程不等待子进程:
import multiprocessing
import time
def worker(name, delay):
print(f"[{name}] 开始工作")
time.sleep(delay)
print(f"[{name}] 工作结束")
def main():
print("[主进程] 启动")
# 定义子进程,分别设置不同的延迟
process1 = multiprocessing.Process(target=worker, args=('子进程1', 5))
process2 = multiprocessing.Process(target=worker, args=('子进程2', 2))
# 启动子进程
process1.start()
process2.start()
# 主进程继续执行自己的任务
print("[主进程] 在等待子进程执行...")
time.sleep(1) # 在等待子进程执行一些任务
print("[主进程] 自己的工作结束了")
# 在这里,没有调用 join(),主进程不会等待子进程完成,虽然它们会继续运行直到自己结束。
if __name__ == "__main__":
main()

结果观察:
- 主进程的任务在它自己的休眠(1秒)后结束,打印出结束通知。
- 子进程会继续执行未完成的任务直到结束(
子进程1将晚于主进程结束大约4秒,因为它被设定工作5秒)。
这样可以看到,虽然子进程会完成自己的处理,但主进程不会默认等待它们的结束,除非显式调用 join() 来等待。如果你希望主进程等待子进程的结束,应该使用 join()。
import multiprocessing
import time
def worker(name, delay):
print(f"[{name}] 开始工作")
time.sleep(delay)
print(f"[{name}] 工作结束")
def main():
print("[主进程] 启动")
# 定义子进程,分别设置不同的延迟
process1 = multiprocessing.Process(target=worker, args=('子进程1', 5))
process2 = multiprocessing.Process(target=worker, args=('子进程2', 2))
# 启动子进程
process1.start()
process2.start()
# 使用 join 等待子进程完成
process1.join() # 等待子进程1完成
process2.join() # 等待子进程2完成
print("[主进程] 所有子进程已完成")
if __name__ == "__main__":
main()

通过设置守护进程方式,使用守护进程使得子进程在主进程完成后立即被终止
import multiprocessing
import time
def worker(name, delay):
while True: # 无限循环,演示守护进程
print(f"[{name}] 正在工作")
time.sleep(delay)
def main():
print("[主进程] 启动")
# 定义子进程,并设置为守护进程
process1 = multiprocessing.Process(target=worker, args=('守护进程1', 1), daemon=True)
process2 = multiprocessing.Process(target=worker, args=('守护进程2', 1), daemon=True)
# 启动子进程
process1.start()
process2.start()
# 主进程继续执行自己的任务
print("[主进程] 正在执行任务...")
time.sleep(3) # 主进程执行一段时间任务
print("[主进程] 结束")
if __name__ == "__main__":
main()

结果观察:
- 主进程结束后,所有守护子进程将被立即终止。
- 输出会显示守护进程在主进程结束后停止打印。
这种使用守护进程的方式适合于后台服务或非关键子任务,子进程不会阻止主进程退出,但没有提供主进程等待子进程完成机会——符合某些任务场景中清理和释放资源的需求。
发布者:LJH,转发请注明出处:https://www.ljh.cool/42240.html