
setting.py 配置文件
在 Django 的 settings.py 文件中,LANGUAGE_CODE 和 TIME_ZONE 是重要的配置选项,它们分别用于设置语言代码和时区。这两个设置可以根据您的需求进行自定义,但有一些规范和建议需要遵循。
LANGUAGE_CODE
LANGUAGE_CODE 用于指定您应用的默认语言。默认为:
LANGUAGE_CODE = 'en-us' # 英文(美国)- 可用值:
- 该值应该是有效的语言代码,通常使用 ISO 639-1 标准(两个字母的语言代码)和国家/地区的 ISO 3166-1 标准(两个字母的国家代码),以连字符(
-)连接。 - 常见值:
- 英文(美国):
'en-us' - 中文(简体):
'zh-hans' - 中文(繁体):
'zh-hant' - 西班牙语:
'es' - 法语:
'fr'
- 英文(美国):
- 该值应该是有效的语言代码,通常使用 ISO 639-1 标准(两个字母的语言代码)和国家/地区的 ISO 3166-1 标准(两个字母的国家代码),以连字符(
TIME_ZONE
定义:TIME_ZONE 用于设置系统的时区。默认为:
TIME_ZONE = 'UTC' # 设置为协调世界时- 可用值:
TIME_ZONE应该是 Django 支持的有效时区,通常可以从 IANA 时区数据库 中查找。- 常见值:
- 协调世界时:
'UTC' - 北京时间:
'Asia/Shanghai' - 纽约时间:
'America/New_York' - 伦敦时间:
'Europe/London'
- 协调世界时:
ALLOWED_HOSTS
定义:安全设置项,用来防止 HTTP Host 头攻击(Host header attack)。它是你项目中的一个列表,用于声明 Django 允许接收请求的主机名(域名或IP)。
settings.py 中的配置示例
ALLOWED_HOSTS = ['localhost', '127.0.0.1', 'www.example.com']注意:runserver 要监听在正确地址。
默认运行:python manage.py runserver 等价于 python manage.py runserver 127.0.0.1:8000,只能本机访问,其他设备访问不到。所以设置正确监听所有地址方式:python manage.py runserver 0.0.0.0:8000或简写为python manage.py runserver 0:8000
静态文件添加
在 Django 项目中,静态文件(如 CSS、JavaScript 和图像文件)的管理和组织是至关重要的。合理地配置静态文件目录可以确保项目的可维护性和性能。以下是关于 Django 项目中静态文件的组织、获取逻辑以及与其他框架的不同之处的详细解释。
项目级别的静态目录结构
将静态文件放在项目的根目录下,通常有一个专门的 static 目录。
mysite/
├── static/
│ ├── css/
│ │ └── style.css
│ ├── js/
│ │ └── script.js
│ └── images/
│ └── my_image.jpg
├── manage.py
└── mysite/
└── settings.py多个 Django 应用,可以在每个应用中创建一个 static 目录,通常结构如下:
blog/
│
├── static/
│ └── blog/
│ ├── css/
│ │ └── blog.css
│ ├── js/
│ │ └── blog.js
│ └── images/
│ └── blog_logo.png
│
├── templates/
│ └── blog/
│ └── index.html
├── models.py
├── views.py
└── ...在 settings.py 中,添加以下配置,告诉 Django 如何处理静态文件:
import os
# BASE_DIR 表示项目根目录
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 静态文件的 URL (即在浏览器中访问时的前缀)
STATIC_URL = '/static/'
# 指定静态文件的文件夹
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static'), # 项目级别的静态文件目录
]
# 你可以使用这个选项来定义不在 STATICFILES_DIRS 里的应用的静态文件的位置,通常不需要手动设置使用静态文件
首先在模板文件顶部加载静态文件的模板标签库:
{% load static %}然后可以使用 {% static %} 标签引用静态文件。例如,引用 CSS 和 JavaScript 文件:
<link rel="stylesheet" type="text/css" href="{% static 'css/style.css' %}">
<script type="text/javascript" src="{% static 'js/script.js' %}"></script>基于项目https://www.ljh.cool/wp-admin/post.php?post=43305&action=edit
继续完善静态文件内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Blog Index</title>
<!-- 加载静态文件 -->
{% load static %}
<link rel="stylesheet" type="text/css" href="{% static 'css/style.css' %}"> <!-- 引用 CSS 文件 -->
<script type="text/javascript" src="{% static 'js/script.js' %}"></script> <!-- 引用 JS 文件 -->
</head>
<body>
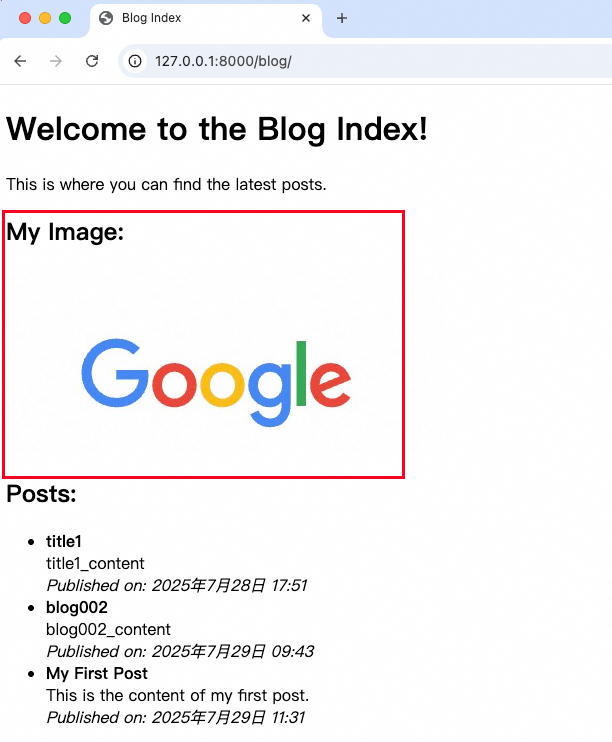
<h1>Welcome to the Blog Index!</h1>
<p>This is where you can find the latest posts.</p>
<!-- 添加静态图片 -->
<h2>My Image:</h2>
<img src="{% static 'images/my_image.jpg' %}" alt="My Image" style="max-width: 100%; height: auto;">
<h2>Posts:</h2>
<ul>
{% for post in posts %}
<li>
<strong>{{ post.title }}</strong><br>
{{ post.content }}<br>
<em>Published on: {{ post.created_at }}</em>
</li>
{% empty %}
<li>No posts available.</li>
{% endfor %}
</ul>
</body>
</html>打开浏览器,访问静态资源,如 http://127.0.0.1:8000/static/images/my_image.jpg


通过访问 http://127.0.0.1:8000/blog/ 加载静态资源
apps.py 配置
在 Django 中,每个应用(app)都有一个 apps.py 文件,里面定义了一个应用的配置类。默认情况下,当您创建一个新应用时,Django 会自动为您生成这个文件。
在 apps.py 中,您将定义一个继承自 django.apps.AppConfig 的类。这个类主要包含以下内容:
- 名称 (
name):指定应用的名称,通常是该应用的模块名。 - 标签 (
label):用于唯一标识该应用的标签,可以是与名不同(可选)。 - 初始化 (
ready):这是用于初始化日志、信号等的地方。
使用 AppConfig
信号(Signals):Django 信号框架用来处理在特定事件发生时自动执行的逻辑。例如,您可以在创建模型实例时发送通知或记录日志。
应用信号:如果您使用了 Django 的信号机制(例如 post_save 或 pre_save),通常会在 ready 方法中进行连接。示例如下:
from django.apps import AppConfig
from django.db.models.signals import post_save
from django.dispatch import receiver
from .models import Post
class BlogConfig(AppConfig):
name = 'blog'
verbose_name = "Blog Application"
def ready(self):
# 在这里连接信号
from . import signals信号的工作原理
- 信号 是 Django 的一种机制,允许应用程序在某些事件发生时执行特定的操作。例如,当新的
Post模型实例被保存时,您可能希望自动执行某些操作(如更新其他模型、发送通知等)。 post_save信号 是在模型实例保存后自动发送的信号。您可以定义一个接收器(receiver)函数来响应这个信号:
@receiver(post_save, sender=Post)
def post_save_handler(sender, instance, created, **kwargs):
if created:
print(f"New post created: {instance.title}")
else:
print(f"Post updated: {instance.title}")以下是一个示例 apps.py 文件的结构,以 blog 应用为例:
from django.apps import AppConfig
class BlogConfig(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'blog'
verbose_name = "Blog Application" # 应用的可读名称default_auto_field = 'django.db.models.BigAutoField'- 从 Django 3.2 开始,引入了
default_auto_field选项来指定生成模型主键的默认类型。BigAutoField是一个 64 位整数,可以自动递增,适用于希望支持更大数量记录的应用。 - 使用
BigAutoField比较适合大型应用,因为它允许比默认的AutoField(32 位整数)支持更多的记录。
这个配置类有什么用?
- 全局配置:
AppConfig可以用于管理 Django 应用的元数据,配置如自动字段、显示名称等。 - 信号连接:在将来使用信号(如保存、删除模型时)时,您可以在类的
ready方法中设置信号的连接。 - 更容易的管理和扩展:通过使用应用程序配置,您能够灵活地管理应用程序的行为。例如,您可以根据环境变量来设置特定于环境的行为。
model.py 模型概述
Django 模型是用于定义数据结构的 Python 类,通常继承自 django.db.models.Model。模型允许开发者通过 Python 代码描述数据库中的表和字段,Django 的 ORM(对象关系映射)自动将模型转换为数据库表。
为什么使用模型?
- 数据抽象:通过模型,您无需直接编写 SQL 语句,Django 会处理与数据库的交互。
- 数据验证:模型字段提供数据类型和约束,Django 在处理数据前进行验证。
- 易于维护:模型使代码更清晰,便于集中管理与数据相关的逻辑。
Django 模型组成部分
1、类定义:
模型定义为一个 Python 类,例如:
from django.db import models
class Post(models.Model):
...2、字段定义:
模型属性定义为字段,设置数据类型和约束。常用字段类型包括:
- CharField:用于存储短文本。需要设置最大长度。
- TextField:用于存储长文本,没有长度限制。
- IntegerField:用于存储整数。
- FloatField:用于存储浮点数。
- DecimalField:用于存储固定精度的十进制数,适合金融计算。
- DateField:用于存储日期。
- DateTimeField:用于存储日期和时间。
- BooleanField:用于布尔值(True 或 False)。
- EmailField:用于存储电子邮件地址,自动验证格式。
- URLField:用于存储 URL 地址。
- ImageField/FileField:用于处理文件上传。
3、方法定义:
可以定义方法增加业务逻辑,例如重载 __str__ 方法,使其返回可读字符串表示。
def __str__(self):
return self.titleDjango 模型字段选项
null:指示数据库是否可以存储 NULL 值。
title = models.CharField(max_length=200, null=True)blank:控制该字段在表单中是否可留空。
title = models.CharField(max_length=200, blank=True)unique:指示字段在整个表中必须保持唯一性。
email = models.EmailField(unique=True)default:设置字段的默认值。
status = models.CharField(max_length=20, default='draft')完整的模型示例
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=200, null=False, blank=False, unique=True)
content = models.TextField(null=True, blank=True)
author_email = models.EmailField(unique=True)
price = models.DecimalField(max_digits=10, decimal_places=2, default=0.00)
created_at = models.DateTimeField(auto_now_add=True)
is_published = models.BooleanField(default=False)
def __str__(self):
return self.title在修改模型后,需要运行以下命令生成并应用迁移,以更新数据库结构:
python manage.py makemigrations # 生成迁移文件
python manage.py migrate # 更新数据库利用 Django ORM 进行操作
使用 Django ORM,通过创建、查询、更新和删除记录进行数据操作:
# 创建记录
new_post = Post(title="My First Post", content="This is the body of my post.")
new_post.save() # 保存到数据库
# 查询记录
all_posts = Post.objects.all() # 获取所有文章
specific_post = Post.objects.get(id=1) # 获取特定文章
# 更新记录
post_to_update = Post.objects.get(id=1)
post_to_update.title = "Updated Title"
post_to_update.save() # 保存更改
# 删除记录
post_to_delete = Post.objects.get(id=1)
post_to_delete.delete() # 删除该文章模型外键定义
在 Django 中,您可以使用 ForeignKey 字段在模型中建立外键关系。下面是如何实现的详细示例。
假设我们要创建一个博客应用,其中的 Post 模型可以有许多评论(Comment),而每个评论是对应某个帖子的。您可以在 Comment 模型中定义一个外键来指向 Post 模型。
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=200, null=False, blank=False, unique=True)
content = models.TextField(null=True, blank=True)
created_at = models.DateTimeField(auto_now_add=True)
def __str__(self):
return self.title
class Comment(models.Model):
post = models.ForeignKey(Post, on_delete=models.CASCADE) # 外键字段,用于链接到 Post
content = models.TextField(null=False, blank=False) # 评论内容
created_at = models.DateTimeField(auto_now_add=True) # 评论创建时间
def __str__(self):
return f'Comment on {self.post.title}' # 显示评论相关的帖子标题重要参数说明
在 ForeignKey 中,您可以设置一些重要的参数:
on_delete:指示当关联的对象被删除时,外键字段的行为。
models.CASCADE:级联删除,如果关联的帖子被删除,则相关的评论也会被删除。models.SET_NULL:设置为NULL,前提是外键字段允许NULL。models.PROTECT:防止删除关联对象,如果尝试删除将抛出错误。models.SET_DEFAULT:将外键设置为字段的默认值。
related_name:用于指定反向关系的名称。在 Comment 模型中可以定义反向关系。例如:
post = models.ForeignKey(Post, on_delete=models.CASCADE, related_name='comments')这样可以通过 post_instance.comments.all() 获取与该 post_instance 相关的所有评论。
Django ORM 和外键的使用
有了外键字段后,您可以用 Django 的 ORM 轻松查询和管理这两个模型之间的关系。
创建记录
# 创建一个 Post
new_post = Post(title="My First Post", content="This is the content of my first post.")
new_post.save()
# 创建与 Post 关联的 Comment
comment1 = Comment(post=new_post, content="Great post!")
comment1.save()查询记录
你可以从 Post 模型中获取所有相关的评论:
post = Post.objects.get(id=1) # 获取 ID 为 1 的帖子
comments = post.comments.all() # 获取与该帖子关联的所有评论
for comment in comments:
print(comment.content)修改表名
以下是如何在 Django 中修改表名的示例:
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=200, null=False, blank=False, unique=True)
content = models.TextField(null=True, blank=True)
created_at = models.DateTimeField(auto_now_add=True)
class Meta:
db_table = 'custom_post_table' # 指定自定义表名在这个例子中,db_table 属性被设置为了 'custom_post_table',这意味着即使 Django 的默认行为下表名为 blog_post(即应用名称加下划线和模型名称),实际在数据库中将会创建一个名为 custom_post_table 的表。
注意事项:如果已经迁移过数据库并且希望修改表名,您需要执行以下步骤:
- 修改模型的
Meta类以包含db_table。(添加class Meta: db_table =’xxx’) - 执行
makemigrations命令生成迁移文件。(python manage.py makemigrations) - 执行
migrate命令更新数据库。(python manage.py migrate)
枚举类型
枚举(enum)是一种特殊的类型,可以让你定义一组固定和有限的选项。比如,你可以用它来表示文章的状态,比如 “草稿”(draft)、”已发布”(published)和 “归档”(archived)。使用枚举可以让你的代码更清晰,避免使用字符串。
为什么使用枚举?
- 限制选项:它只允许你选择特定的值。比如,对于文章的状态,你只能选择 “草稿”、”已发布” 或 “归档”。
- 易于维护:如果你想改变或添加状态,只需要在一处修改,不需要到处找。
在 Django 中,你可以通过模型的 choices 属性来使用枚举。这里有一个简单的例子:
from django.db import models
class Post(models.Model): # 定义一个 Post 类(文章)
# 定义文章状态的三个选项
class Status(models.TextChoices):
DRAFT = 'draft', '草稿'
PUBLISHED = 'published', '已发布'
ARCHIVED = 'archived', '归档'
# 定义标题字段
title = models.CharField(max_length=200, unique=True) # 限制最多200个字符,且名称必须唯一
# 定义内容字段
content = models.TextField() # 可以存储任意长的文本
# 定义状态字段,用于选取枚举值
status = models.CharField(max_length=10,
choices=Status.choices, # 允许的选项
default=Status.DRAFT) # 默认状态是草稿
# 创建时间,自动设置为当前时间
created_at = models.DateTimeField(auto_now_add=True)
def __str__(self):
return self.title # 显示文章的标题- 状态定义:我们创建了一个内部类
Status,通过TextChoices定义了三个状态:DRAFT值为'draft',中文显示为'草稿'PUBLISHED值为'published',中文显示为'已发布'ARCHIVED值为'archived',中文显示为'归档'
- 标题和内容:
title字段是用来存文章的标题,而content字段是用来存文章的内容。 - 状态字段:
status字段定义了可以选择的状态,它只能是'draft'、'published'或'archived'中的一个。- 如果没有手动设置状态,默认值是
'draft'。
修改数据库引擎
我这里在 macOS 上操作,对于 Ubuntu 或 windows 用户自行搜索文档:
步骤 1: 安装 MySQL:
brew install mysql步骤 2: 安装 mysqlclient 库
安装相关的开发工具:
安装 mysql 和 pkg-config 依赖
brew install mysql pkg-configpkg-config是编译期间用来寻找头文件和库路径的工具mysql安装后会带有mysql_config
您可能需要安装 pkg-config 及一些开发库。
brew install pkg-config
brew install openssl
brew install mariadb-connector-c设置环境变量(在虚拟环境中配置)
export PATH="/usr/local/opt/openssl/bin:$PATH"
export LDFLAGS="-L/usr/local/opt/openssl/lib"
export CPPFLAGS="-I/usr/local/opt/openssl/include"安装 mysqlclient:
pip install mysqlclient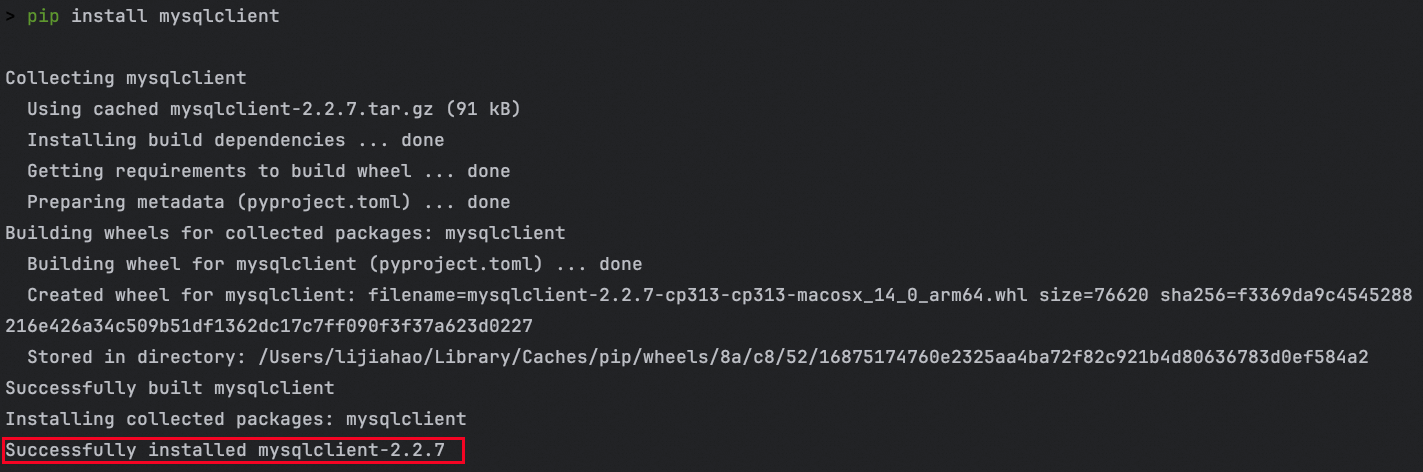
步骤 3: 修改 settings.py 配置
打开 Django 项目中的 settings.py 文件,找到 DATABASES 部分。您需要将其更改为 MySQL 数据库的配置。以下是一个使用 MySQL 的示例配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 设置为 MySQL
'NAME': 'your_database_name', # 您的数据库名称
'USER': 'your_username', # 您的用户名
'PASSWORD': 'your_password', # 您的密码
'HOST': 'localhost', # 数据库主机
'PORT': '3306', # MySQL 的默认端口
}
}步骤 4: 创建数据库
创建您在 settings.py 中指定的数据库:
CREATE DATABASE your_database_name CHARACTER SET UTF8mb4 COLLATE utf8mb4_unicode_ci;步骤 5: 迁移数据
在修改数据库引擎并创建数据库后,您需要运行以下命令来生成迁移文件并应用迁移,以在新的 MySQL 数据库上创建所有表:
python manage.py makemigrations
python manage.py migrate步骤 6: 测试连接
python manage.py runserver ,然后在浏览器中访问 http://127.0.0.1:8000/,查看应用是否正常工作。
例如:我们将https://www.ljh.cool/43305.html的数据库从 sqlite3 迁移到 mysql 过程:
# 创建数据库:
CREATE DATABASE blog_db CHARACTER SET UTF8mb4 COLLATE utf8mb4_unicode_ci;
# 修改 settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 设置为 MySQL
'NAME': 'blog_db', # 您的数据库名称
'USER': 'root', # 您的用户名
'PASSWORD': 'XXXXXXXX', # 您的密码
'HOST': 'localhost', # 数据库主机
'PORT': '3306', # MySQL 的默认端口
}
}
# 迁移数据
python manage.py makemigrations
python manage.py migrate查看迁移结果:
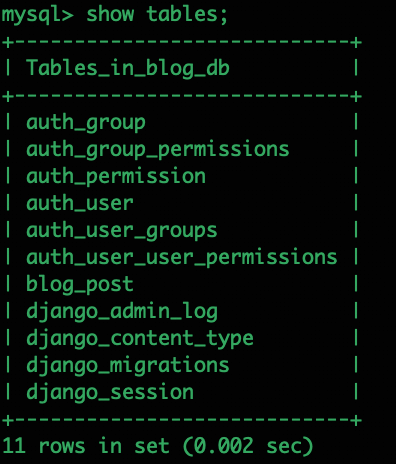
后台登录插入一些内容,查看数据库是否成功插入

额外补充:假如使用pymysql
如果您使用 mysqlclient 并且成功地连接了 MySQL 数据库,那么您无需进行额外的配置。默认情况下,Django 会自动识别 mysqlclient。但是,如果您决定使用 pymysql 作为 MySQL 的数据库驱动程序,您需要在 Django 项目的 __init__.py 文件中添加以下代码:
在 mysite/__init__.py 中添加:
import pymysql
pymysql.install_as_MySQLdb()这段代码的作用是让 pymysql 作为 MySQLdb 库来使用,因为 Django 的 MySQL 数据库后端默认是 MySQLdb。这就可以确保 Django 可以使用 pymysql 来与 MySQL 数据库进行交互。如果不在工程包中导入pymysql,会在执行迁移时报错:No module named ‘MySQLdb’
Python 的 shell 调试 Django 应用程序
使用 Python 的 shell(REPL 环境)来调试 Django 应用程序可以帮助您理解 ORM(对象关系映射)如何工作,以及如何与数据库交互。您可以在 Django 的 shell 中执行操作,查询数据库等。
使用 Django Shell
在 Django 项目的根目录下(与 manage.py 位于同一目录)打开命令行或终端,然后输入以下命令进入 Django shell:
python manage.py shell这将启动一个 Python 交互式 shell,您可以在其中直接使用 Django 的模型和功能。
一些基本操作
导入模型:
首先,您需要导入 Post 模型:
from blog.models import Post这里的 blog 是您的 Django 应用名称,如果您的应用名称不同,请相应地更改。
创建新文章:
例如,您可以使用以下代码创建一个新的 Post 实例:
实例方法创建
new_post = Post(title="My First Post", content="This is the content of my first post.")
new_post.save() # 保存到数据库查询集方法创建
在需要更多灵活性和控制的情况下,使用 .save() 方法会更合适。如果您仅仅是创建新对象并保存,无需复杂逻辑,Post.objects.create() 可能是更为优雅和简洁的选择。
Post.objects.create(title="My Second Post", content="This is the content of my second post.")批量创建
使用 bulk_create() 方法可以一次性创建多个对象。例如,假设我们要创建多个新的 Post 对象,可以这样做:
from yourapp.models import Post # 替换为你的实际应用和模型导入
# 创建多个 Post 对象
posts_to_create = [
Post(title="博客文章 1", content="内容 1", status="已发布"),
Post(title="博客文章 2", content="内容 2", status="草稿"),
Post(title="博客文章 3", content="内容 3", status="已发布"),
]
# 批量创建
Post.objects.bulk_create(posts_to_create)- 实例方法适合于你需要获取具体的对象实例时,便于后续对该实例的其他操作。
- 查询集方法适合于批量操作,且更为高效和简洁,特别是在处理大量数据时。
更新文章:
您可以更新某个文章的标题或内容:
实例方法更新
post = Post.objects.get(id=1) # 获取 ID 为 1 的 Post
post.title = "修改标题后的博客文章 1" # 更新标题
post.save() # 保存更改查询集方法更新
当你要更新多条记录时,可以使用 update() 方法借助 filter() 来实现 。filter() 返回的结果是多个对象的列表
Post.objects.filter(id=1).update(title="修改标题后的博客文章 1")删除文章:
使用 get() 方法获取对象并调用 delete() 方法来删除数据
post_to_delete = Post.objects.get(id=1) # 获取要删除的 Post
post_to_delete.delete() # 删除该 Post使用 filter() 方法结合 delete() 方法来删除数据
Post.objects.filter(id=1).delete()Django Shell 查询操作(重点)
目前数据库内容:

1. 查询所有文章:
获取所有的帖子并输出它们:
posts = Post.objects.all() # 获取所有 Post 数据,返回结果为列表
for post in posts:
print(post.title) # 打印每个 Post 的标题2. 获取特定文章:
如果您知道某个帖子的 ID,可以轻松获取该帖子的内容:
post = Post.objects.get(id=1) # 根据 ID 获取 Post,使用 get() 返回结果为单个对象
print(post.content) # 打印该 Post 的内容3. 使用特定字段查询:
如果不知道帖子的 ID,可以通过其他属性进行查询。例如,通过标题或作者:
例如通过标题查询(如果查询的结果不存在,建议进行异常捕获)
# 假设要查找标题为 "博客文章 1" 的 Post
try:
post = Post.objects.get(title="博客文章 1") # 根据标题获取 Post
print(post.content) # 打印该 Post 的内容
except Post.DoesNotExist:
print("没有找到该标题的帖子")4. 使用 filter() 方法
filter() 方法可以用来根据某些条件获取多个对象。可以链式使用多个过滤条件:
# 获取状态为 "已发布" 的所有文章
published_posts = Post.objects.filter(status='已发布')
for post in published_posts:
print(post.title)你还可以使用 Q 对象组合查询条件,支持 OR 查询:
假设你想查找标题包含 “博客” 或者内容中包含 “first” 的文章。可以使用 Q 对象:
from django.db.models import Q
# 查询标题包含 "博客" 或内容中包含 "first" 的帖子
posts = Post.objects.filter(Q(title__icontains='博客') | Q(content__icontains='first'))
for post in posts:
print(f'Title: {post.title}, Content: {post.content}')5. 排序和限制结果
你可以使用 order_by() 方法对查询结果进行排序,使用 first() 或 last() 获取第一条或最后一条记录。
# 获取按发布日期降序排列的所有文章
# 按创建时间降序获取所有文章
posts = Post.objects.order_by('-created_at')
for post in posts:
print(f'Title: {post.title}, Created At: {post.created_at}')
# 获取创建时间最新的文章
latest_post = Post.objects.order_by('-created_at').first()
if latest_post:
print(f'最新文章: Title: {latest_post.title}, Created At: {latest_post.created_at}')6. 使用切片
你可以使用切片来限制返回的结果数,例如获取前十条记录:
# 获取前两篇文章
top_two_posts = Post.objects.all()[:2]
for post in top_two_posts:
print(f'Title: {post.title}, Created At: {post.created_at}')7. 计数
你可以使用 count() 方法获取符合某个条件的记录数:
# 获取文章总数
total_posts = Post.objects.count()
print(f'总文章数: {total_posts}')Django ORM 构建新表
我们要创建两个新的表:Author 表和 Comment 表
在 models.py 文件中定义两个新表对象:
from django.db import models # 导入 Django 的模型包,模型定义替代了数据库表的设计
# 定义作者模型,表示每个博客的作者
class Author(models.Model):
name = models.CharField(max_length=100) # 作者的名字,使用 CharField 字段类型,最大长度为 100
bio = models.TextField(blank=True, null=True) # 作者介绍,使用 TextField 字段,允许空值和 blank(不强制填写)
def __str__(self):
return self.name # 返回作者名称,用于表示该对象,比如在 Django Admin 中方便查看
# 定义帖子模型,表示每篇博客文章
class Post(models.Model):
title = models.CharField(max_length=200) # 帖子的标题,使用 CharField,最大长度为 200
content = models.TextField() # 帖子的内容,使用 TextField,可以容纳长文本
created_at = models.DateTimeField(auto_now_add=True) # 帖子创建时间,使用 DateTimeField,会在创建时自动设置为当前时间
author = models.ForeignKey(Author, on_delete=models.CASCADE, related_name='posts') # 与 Author 模型之间的一对多关系,关联作者
def __str__(self):
return self.title # 返回帖子的标题,方便在代码中的显示
# 定义评论模型,表示对帖子进行的评论
class Comment(models.Model):
post = models.ForeignKey(Post, on_delete=models.CASCADE, related_name='comments') # 与 Post 模型之间的外键关系,一个评论属于一个帖子
author = models.ForeignKey(Author, on_delete=models.CASCADE) # 与 Author 之间的外键关系,一个评论由一个作者创建
content = models.TextField() # 评论内容,使用 TextField,允许长文本
created_at = models.DateTimeField(auto_now_add=True) # 评论创建时间,自动设置为当前时间
def __str__(self):
# 返回格式化的字符串,显示评论作者及其评论的帖子标题
return f'Comment by {self.author.name} on {self.post.title}'
创建迁移文件并应用
# 创建迁移文件
python manage.py makemigrations
# 应用迁移到数据库
python manage.py migrate注意:刷新迁移
在已迁移的数据库中重置数据库需要先删除 migrations/0001_initial.py 文件
如果遇到下面返回结果:
> python manage.py makemigrations
Migrations for 'blog':
blog/migrations/0001_initial.py
+ Create model Author
+ Create model Post
+ Create model Comment
(venv)
但是再执行迁移时没有进行迁移:
> python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, blog, contenttypes, sessions
Running migrations:
No migrations to apply.
下面我们需要进行操作:
python manage.py migrate blog zero --fake # 让 Django 模拟重置状态而不实际删除任何东西
python manage.py migrate blog # 重新应用 blog 应用的迁移测试数据的插入
python manage.py shell在 shell 中执行:
from blog.models import Author, Post, Comment # blog 修改为你的应用名
# 创建作者
author1 = Author.objects.create(name="用户A", bio="技术爱好者")
author2 = Author.objects.create(name="用户B", bio="博客写手")
# 创建帖子
post1 = Post.objects.create(title="Django 入门", content="这是关于Django的基本知识.", author=author1)
post2 = Post.objects.create(title="Python 进阶", content="深入理解Python的特性.", author=author2)
# 创建评论
Comment.objects.create(post=post1, author=author2, content="非常棒的文章!")
Comment.objects.create(post=post1, author=author1, content="谢谢!")
Comment.objects.create(post=post2, author=author2, content="图文并茂,学习到了很多!")插入结果:
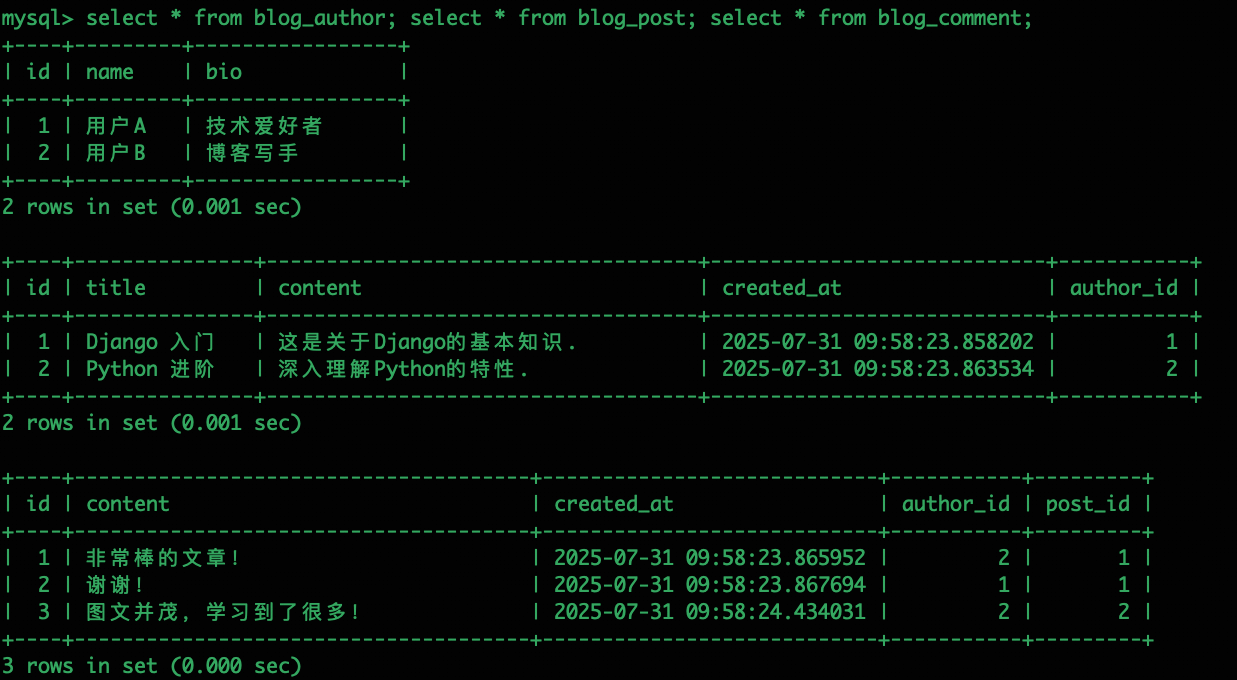
ORM 常见数据操作
1. F 对象
用途:F 对象允许你在查询中引用模型字段的值,以便进行比较、算术运算等。这在需要根据同一模型的不同字段进行操作时非常有用。
示例:
blog_comment表中找出 author_id > post_id 的评论
Comment.objects.filter(author_id__gt=F('post_id'))
假设你有一个 Post 模型,包含 likes 字段。你想找到所有点赞数大于 10 的帖子,并增加它们的点赞数。
from django.db.models import F
# 增加点赞数
Post.objects.filter(likes__gt=10).update(likes=F('likes') + 1) # 增加点赞数使用 F 对象优势:
- 避免数据的冗余处理:通过使用
F对象,您可以在数据库层面直接进行操作,减少了在应用程序中有效处理数据的需要,减轻了内存占用。 - 提高性能:
F对象允许 Django 直接与数据库交互,从而减少了网络流量,比起在内存中取出记录后再进行处理,能够提高性能。
2. Q 对象
用途:Q 对象用于构建复杂查询,支持逻辑运算符(如 AND、OR)(使用 &(与)和 |(或)来组合条件)。它使得组合多个查询条件变得更加灵活。
示例:
查找所有由“用户A”创作的帖子,或者评论内容中包含“图文并茂”的帖子:
from django.db.models import Q
posts = Post.objects.filter(Q(author__name='用户A') | Q(comments__content__icontains='图文并茂')).distinct()
for post in posts:
print(f'Title: {post.title}, Author: {post.author.name}')- 或:Q() | Q()
- 且:Q() & Q()
- 非:~Q()
3. 聚合函数
用途:
Django 提供了一些内置的聚合函数(如 Sum、Count、Avg、Max 和 Min),用于在查询中获取统计信息。
示例:
获取每个作者所创作的帖子数量:
from django.db.models import Count
# 使用 annotate() 方法与 Count() 函数获取每个作者的帖子数量
authors_with_post_count = Author.objects.annotate(post_count=Count('posts'))
for author in authors_with_post_count:
print(f'Author: {author.name}, Post Count: {author.post_count}')4. 关联查询
用途:
通过外键关系在查询中涉及多个表。Django ORM 允许通过模型属性轻松进行多表查询。
示例:
获取所有评论以及对应的帖子标题和作者:
comments = Comment.objects.select_related('post', 'author') # 使用 select_related 来优化查询
for comment in comments:
print(f'Comment by {comment.author.name} on post "{comment.post.title}": {comment.content}')5. 使用 annotate() 进行复杂查询
用途:annotate() 方法用于在查询集上添加计算字段,以汇总数据或计算汇总值。
示例:
获取每个帖子的评论数量:
from django.db.models import Count
posts_with_comment_count = Post.objects.annotate(comment_count=Count('comments'))
for post in posts_with_comment_count:
print(f'Post: {post.title}, Comment Count: {post.comment_count}')6. 复杂的筛选条件使用 exclude()
用途:exclude() 方法用于从查询结果中排除满足特定条件的记录。
示例:
获取所有不是由“用户A”创作的帖子:
posts_not_by_author_a = Post.objects.exclude(author__name='用户A')
for post in posts_not_by_author_a:
print(f'Title: {post.title}, Author: {post.author.name}')filter()查询函数过滤条件
基本过滤
field_name=value: 精确匹配字段值。
Post.objects.filter(title="Django 入门")不等于
field_name!=value 或 field_name__ne=value(后者在 Django 中不常用,可以直接使用 exclude())。
Post.objects.filter(title__ne="Django 入门") # 或者直接使用
Post.objects.exclude(title="Django 入门")大小比较
field_name__gt=value: 大于field_name__gte=value: 大于等于field_name__lt=value: 小于field_name__lte=value: 小于等于
Post.objects.filter(created_at__lt="2025-01-01")包含和开头匹配
field_name__icontains=value: 不区分大小写的包含。field_name__contains=value: 区分大小写的包含。field_name__startswith=value: 以指定值开头的匹配。field_name__endswith=value: 以指定值结尾的匹配。
Post.objects.filter(title__icontains="Django")
Post.objects.filter(title__startswith="D")范围查找
field_name__in=[val1, val2, ...]: 包含于指定的列表中。
Post.objects.filter(id__in=[1, 2, 3])日期和时间过滤:
field_name__date=value: 只获取日期部分。field_name__year=value: 只获取年份。field_name__month=value: 只获取月份。field_name__day=value: 只获取天数。
Post.objects.filter(created_at__year=2025)布尔值过滤:
field_name=True或field_name=False:过滤出布尔字段为 True 或 False 的记录。
Post.objects.filter(is_published=True)正则表达式:
field_name__regex=r'正则': 匹配正则表达式。field_name__iregex=r'正则': 不区分大小写的正则匹配。
Post.objects.filter(title__regex=r'^Django') # 匹配以 Django 开头的标题链式过滤:
- 多条件过滤可以通过链式调用
filter()进行:
Post.objects.filter(title='Django 入门').filter(created_at__gt="2025-01-01")使用 Q 对象:
- 可以使用
&(与)和|(或)来组合条件。
from django.db.models import Q
Post.objects.filter(Q(author__name="用户A") | Q(title__icontains="Django"))当你调用 filter() 方法,并传入这样的条件时,Django ORM 会为你的查询自动构建适当的 SQL 查询,包含相应的 JOIN 操作。
SELECT * FROM blog_post
JOIN blog_author ON blog_post.author_id = blog_author.id
WHERE blog_author.name = '用户A' OR blog_post.title LIKE '%Django%'Django 会执行该 SQL 查询,从数据库中获取符合条件的 Post 对象。
聚合函数详解
使用 Django 的内置聚合函数(如 Count、Sum、Avg、Max 和 Min)来获取一些统计信息。
# 示例 1: 计算每个作者的帖子数量
from django.db.models import Count
from blog.models import Author
# 获取每个作者的帖子数量
authors_with_post_count = Author.objects.annotate(post_count=Count('posts'))
for author in authors_with_post_count:
print(f'作者: {author.name}, 帖子数量: {author.post_count}')
# 示例 2: 计算每个帖子的评论数量
from django.db.models import Count
from blog.models import Post
# 获取每个帖子的评论数量
posts_with_comment_count = Post.objects.annotate(comment_count=Count('comments'))
for post in posts_with_comment_count:
print(f'帖子: {post.title}, 评论数量: {post.comment_count}')
# 示例 3: 计算整个博客的评论总数
from django.db.models import Count
# 获取所有评论的数量
total_comments = Comment.objects.count()
print(f'总评论数量: {total_comments}')
# 示例 4: 计算每位作者的平均评论数
from django.db.models import Count, Avg
from blog.models import Author
# 计算每个作者的平均评论数
authors_with_avg_comments = Author.objects.annotate(avg_comments=Avg('posts__comments'))
for author in authors_with_avg_comments:
print(f'作者: {author.name}, 平均评论数: {author.avg_comments}')
# 示例 5: 找出帖子中评论的最大和最小数量
from django.db.models import Count, Max, Min
from blog.models import Post
# 获取每个帖子的评论数量并找出最大和最小值
post_comment_counts = Post.objects.annotate(comment_count=Count('comments'))
max_comment_post = post_comment_counts.aggregate(Max('comment_count'))
min_comment_post = post_comment_counts.aggregate(Min('comment_count'))
print(f'最大评论数: {max_comment_post}')
print(f'最小评论数: {min_comment_post}')Django ORM 排序的核心概念
核心概念
Django 提供的排序功能可以通过 order_by() 方法实现。这个方法用于对查询集结果进行升序或降序排序。
- 升序排序: 使用一个字段的名称。
- 降序排序: 在字段名称前加负号(
-)。 - 多重排序: 可以在
order_by()中传入多个字段,以此进行分层排序。
1. 按照创建时间降序排序帖子
from blog.models import Post
# 按创建时间降序排序
posts_sorted = Post.objects.order_by('-created_at')
for post in posts_sorted:
print(f'标题: {post.title}, 创建时间: {post.created_at}')2. 按照帖子标题升序排序
# 按标题升序排序
posts_sorted_by_title = Post.objects.order_by('title')
for post in posts_sorted_by_title:
print(f'标题: {post.title}')3. 按作者名字升序排序并按创建时间降序排序
# 同时按作者名字升序和创建时间降序排序
posts_sorted_by_author_and_time = Post.objects.select_related('author').order_by('author__name', '-created_at')
for post in posts_sorted_by_author_and_time:
print(f'标题: {post.title}, 作者: {post.author.name}, 创建时间: {post.created_at}')4. 获取评论数最多的前 5 个帖子
from django.db.models import Count
# 获取评论数最多的前 5 个帖子
top_5_posts = Post.objects.annotate(comment_count=Count('comments')).order_by('-comment_count')[:5]
for post in top_5_posts:
print(f'标题: {post.title}, 评论数量: {post.comment_count}')Django ORM 中关联查询的核心概念
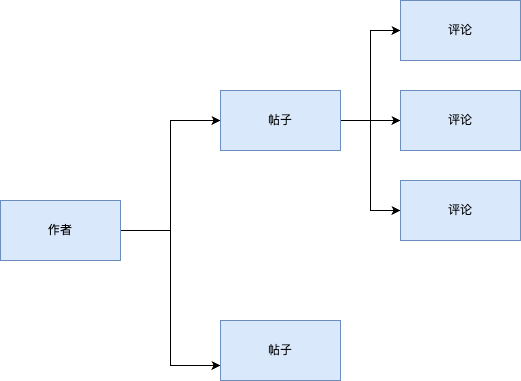
核心概念
Django ORM 支持模型之间的一对一、一对多和多对多关系。通过使用关联查询,你可以轻松地从相关联的模型中获取数据:
select_related(): 用于一对多或多对一关系的前向查询,使用 SQL 的 JOIN 操作,可以在查询时获取相关对象数据,从而减少查询次数。prefetch_related(): 用于多对多或一对多关系的后向查询,执行两次查询(一次查询主对象,一次查询相关对象),适用于可能返回大量结果的查询。
1. 使用 select_related() 查询
获取所有帖子及其作者的信息:
from blog.models import Post
# 获取所有帖子及其作者信息
posts_with_authors = Post.objects.select_related('author').all()
for post in posts_with_authors:
print(f'帖子: {post.title}, 作者: {post.author.name}')解释: 在这个例子中,使用 select_related('author') 来避免对 author 模型的多次查询,这样可以提高效率。
2. 使用 prefetch_related() 查询
获取所有作者及其发布的帖子:
from blog.models import Author
# 获取所有作者及其关联的帖子
authors_with_posts = Author.objects.prefetch_related('posts')
for author in authors_with_posts:
print(f'作者: {author.name}')
for post in author.posts.all():
print(f' 帖子: {post.title}')解释: 这里使用 prefetch_related('posts') 来预加载每个 Author 的 posts,这样每个作者及其帖子都会在单独的查询中加载,从而避免 N+1 查询问题。
3. 使用反向关联查询
找到所有评论以及关联的帖子标题和作者名称:
from blog.models import Comment
# 获取所有评论及其关联的帖子标题和作者名称
comments_with_posts = Comment.objects.select_related('post__author')
for comment in comments_with_posts:
print(f'评论: {comment.content}, 帖子: {comment.post.title}, 作者: {comment.post.author.name}')解释: 在这个例子中,通过 select_related('post__author') 可以直接获取评论相关的帖子及其作者的信息。
核心概念
- 正向获取:
- 正向查询是从子对象获取父对象的信息。通过外键(
ForeignKey)字段,可以直接访问关联的父对象。
- 正向查询是从子对象获取父对象的信息。通过外键(
- 反向获取:
- 反向查询是从父对象获取所有相关的子对象。这通常通过指定的
related_name进行。
- 反向查询是从父对象获取所有相关的子对象。这通常通过指定的
我们有下模型结构:
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
def __str__(self):
return self.name
class Post(models.Model):
title = models.CharField(max_length=200)
content = models.TextField()
author = models.ForeignKey(Author, related_name='posts', on_delete=models.CASCADE)
def __str__(self):
return self.title
class Comment(models.Model):
post = models.ForeignKey(Post, related_name='comments', on_delete=models.CASCADE)
content = models.TextField()
def __str__(self):
return self.content正向获取示例
从 Post 获取 Author
# 获取某个帖子
post = Post.objects.get(title='Django 入门')
# 获取帖子的作者
author = post.author
print(f'帖子标题: {post.title}, 作者: {author.name}')反向获取示例
从 Author 获取所有 Post
通过 related_name 获取与该作者相关的所有帖子:
# 获取某个作者
author = Author.objects.get(name='用户A')
# 通过 related_name 获取该作者的所有帖子
posts = author.posts.all() # 使用 'posts' 这个 related_name
for post in posts:
print(f'帖子标题: {post.title}')从 Post 获取所有 Comment
通过 related_name 获取与该帖子相关的所有评论:
# 获取某个帖子
post = Post.objects.get(title='Django 入门')
# 通过 related_name 获取该帖子的所有评论
comments = post.comments.all() # 使用 'comments' 这个 related_name
for comment in comments:
print(f'评论内容: {comment.content}')- 正向查询: 通过外键直接访问关联的父对象(如
post.author)。 - 反向查询: 通过
related_name从父对象获取其关联的所有子对象(如author.posts.all())。
使用默认名称和自定义 related_name
1. 默认名称 (_set)
当在定义 ForeignKey 或 ManyToManyField 时,如果没有设置自定义的 related_name,Django 会自动生成一个默认的名称,以小写的模型名称加上 _set 后缀。这样你就可以通过这个默认名称访问与父对象关联的所有子对象。
示例模型
class Author(models.Model):
name = models.CharField(max_length=100)
class Post(models.Model):
title = models.CharField(max_length=200)
author = models.ForeignKey(Author, on_delete=models.CASCADE)在这个例子中,Post 对象与 Author 对象之间存在一对多关系。
使用默认名称获取数据
如果你没有为 author 字段设置 related_name,获取与作者关联的所有帖子时,你需要使用默认名称访问:
# 假设获取某个作者的所有帖子
author = Author.objects.get(name='用户A')
# 使用默认的 _set 名称进行访问
posts = author.post_set.all() # 这里的 post_set 是 Django 生成的默认名称,格式为:主表模型(实例对象).关联模型类名小写_set.all()自定义 related_name: 你可以在外键或多对多字段中自定义 related_name 以便使得访问和查询更为直观和易于理解。如果不设置,Django 会自动生成一个默认值,通常是小写的模型名称加上 _set。
# 没有设置 related_name,使用默认名称
post_set = author.post_set.all() # 使用默认的 '_set' 访问
# 假如自定义了 related_name
posts = author.posts.all() # 使用自定义的相关名称这里,post_set 是 Django 自动生成的查询集名称,它允许你从 Author 对象获取所有相关的 Post 对象。
自定义 related_name
为了使代码更具可读性,您可以在外键字段中定义自定义的 related_name。
修改模型以添加 related_name
class Post(models.Model):
title = models.CharField(max_length=200)
author = models.ForeignKey(Author, related_name='posts', on_delete=models.CASCADE)在这个例子中,我们为 author 字段定义了一个自定义的 related_name 为 posts。
现在就可以通过自定义的 related_name 来访问与作者关联的所有帖子,你使用的 posts 是你在 ForeignKey 中设置的 related_name,它使得访问更直观,而不是用 _set 这种自动生成的名称。
# 获取某个作者的所有帖子
author = Author.objects.get(name='用户A')
# 使用自定义的 related_name 进行访问
posts = author.posts.all() # 使用自定义的名称 'posts'结合使用模型之间的关系(前向和反向)以及筛选条件来获取特定的数据
1. 基本概念
- 正向查询:通过子对象获取父对象的信息。
- 反向查询:通过父对象获取所有相关的子对象。
- 筛选条件:可以使用
.filter()方法来过滤结果集,使用双下划线(__)语法访问关联的字段进行条件筛选。
找到所有由特定作者(如“用户A”)撰写的帖子
# 获取作者"用户A"
author_a = Author.objects.get(name='用户A')
# 获取该作者的所有帖子
posts_by_author_a = author_a.posts.all() # 使用 related_name
for post in posts_by_author_a:
print(f'帖子标题: {post.title}')根据作者的名字来筛选所有帖子,可以使用 .filter() 结合双下划线(__):
# 筛选所有由"用户A"创作的帖子
posts_by_author_a = Post.objects.filter(author__name='用户A')
for post in posts_by_author_a:
print(f'帖子标题: {post.title}')筛选由”用户A”创建的帖子,并且这些帖子必须有评论
# 筛选由"用户A"创建的帖子,并且这些帖子必须有评论
posts_with_comments = Post.objects.filter(
author__name='用户A', # 查找作者为"用户A"的帖子
comments__content__isnull=False # 确保这些帖子有评论
).distinct() # 使用 distinct() 防止重复的帖子记录
# 输出结果
for post in posts_with_comments:
print(f'标题: {post.title},作者: {post.author.name}') # 输出帖子的标题和作者
for comment in post.comments.all(): # 获取该帖子的所有评论
print(f' 评论内容: {comment.content}') # 输出每条评论的内容QuerySet 结果集
查询结果集在 Django ORM 中是通过 QuerySet 表示的,用于管理和操作从数据库中检索的对象。它支持链式查询、切片、计数以及迭代等操作。
QuerySet 的基本概念
- 定义: QuerySet 是通过
Model.objects.all()、Model.objects.filter()、Model.objects.exclude()、Model.objects.order_by()方法返回的一系列数据库记录,这些记录可以是一个或多个。 - 延迟加载:QuerySet 是懒加载的,这意味着它不会立即从数据库中获取数据,直到需要的时候(例如,当你迭代 QuerySet 或在模板中渲染数据时)。
- 可链式调用: QuerySet 可以通过方法链组合。您可以在一个 QuerySet 上进行多个筛选条件,而每个筛选都会返回新 QuerySet。
- 假设我们使用先前定义的
Author、Post和Comment模型进行查询。
# 获取所有帖子
all_posts = Post.objects.all()
# 获取特定条件的帖子
posts_by_author_a = Post.objects.filter(author__name='用户A')查询结果集的操作:
# 迭代: 你可以遍历 QuerySet,例如:
for post in all_posts:
print(post.title)
# 切片: 和列表相似,你可以对 QuerySet 进行切片,获取其中的一部分记录:
first_three_posts = Post.objects.all()[:3] # 获取前3个帖子的 QuerySet
# 计数: 可以使用 .count() 方法获取 QuerySet 中的记录数量:
number_of_posts = Post.objects.all().count() # 计算所有帖子的数量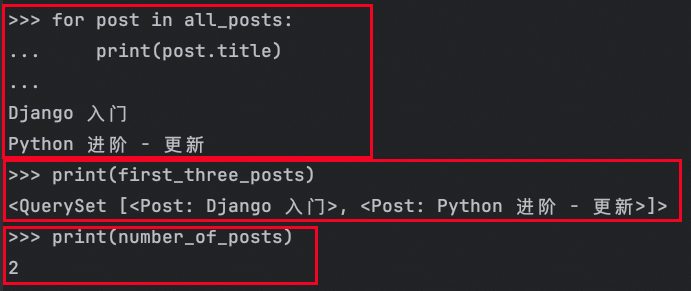
结果集的特性
- 可序列化: QuerySet 可以被序列化为 JSON,可以直接用于 API 响应。
- 从 QuerySet 到列表: 如果您需要结果集的列表,可以通过转换:
posts_list = list(Post.objects.all()) # 变为列表ORM 分页操作
什么是分页(Pagination)
分页的本质是:
当数据量太大时,一次性返回所有数据太重,我们希望”一页只返回一部分数据”。
比如你有 100 篇博客,一次只显示 10 篇,那么你就需要分页来控制每次返回的数据范围(例如第1页10条,第2页10条……)。
Django 提供的分页工具
from django.core.paginator import Paginator它可以把一个QuerySet(如 Post.objects.all())分页成一页一页的数据,非常方便地控制每页几条、查看第几页。
示例:分页展示博客文章
from django.core.paginator import Paginator
from blog.models import Post # 替换为你的 app 名
# 第一步:获取所有博客文章(QuerySet)
all_posts = Post.objects.all().order_by('-created_at') # 按创建时间倒序排列
# 第二步:创建分页器,每页2条(你可以改为任意数)
paginator = Paginator(all_posts, 2)
# 第三步:获取某一页的数据,比如获取第1页
page_number = 1 # 假设我们想获取第1页
page_obj = paginator.get_page(page_number)
# 第四步:打印这一页的帖子
for post in page_obj:
print(post.title, post.created_at, post.author.name)分页对象 page_obj 有什么用?
page_obj 是当前页的对象,它不仅包含当前页的数据,还包含一些分页相关的属性,例如:
page_obj.has_next() # 是否还有下一页
page_obj.has_previous() # 是否有上一页
page_obj.number # 当前页码
page_obj.paginator.num_pages # 总页数
page_obj.paginator.count # 总记录数发布者:LJH,转发请注明出处:https://www.ljh.cool/43387.html