
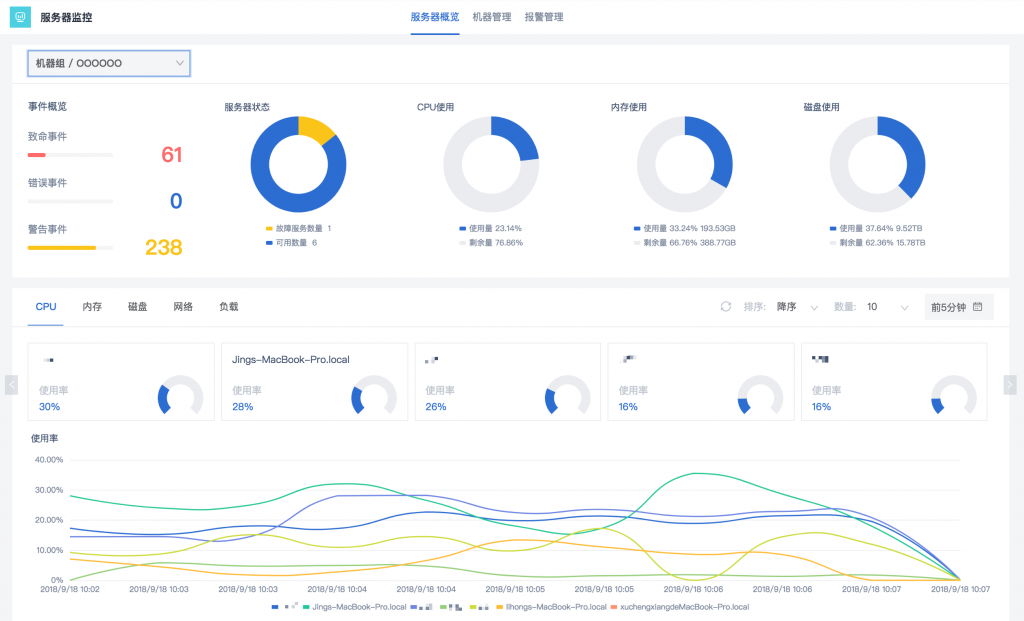

监控概念
要监控什么
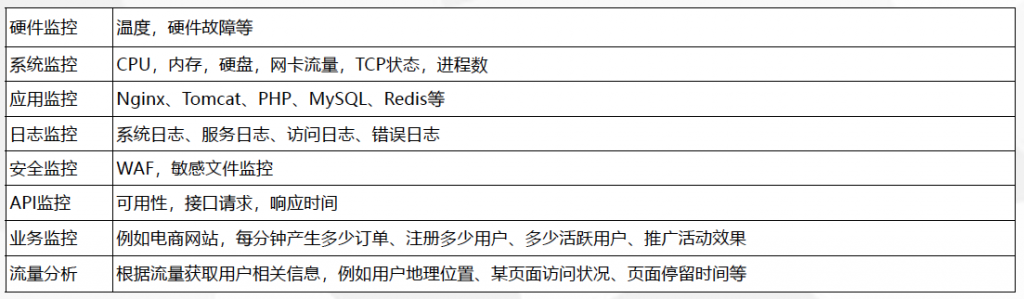
怎么来监控

•熟悉被监控对象
•整理监控指标
•告警阈值定义
•故障处理流程
大型企业监控流程
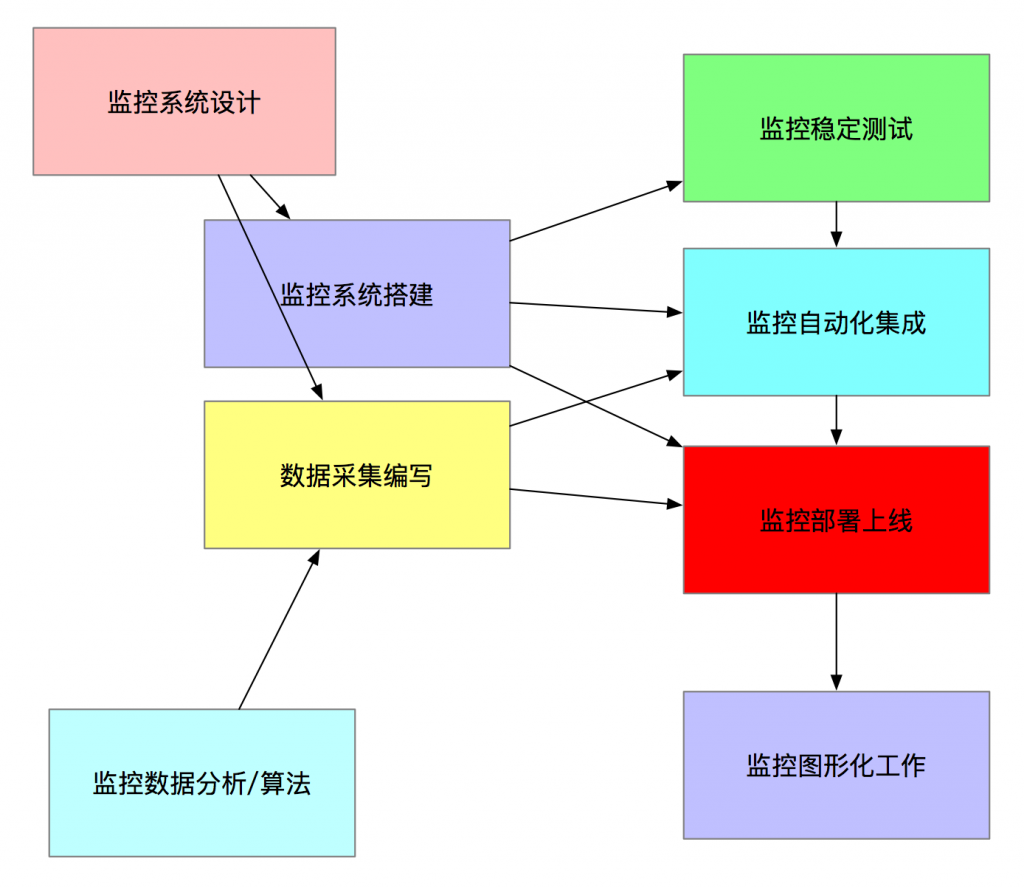
监控系统设计(架构师):
设计部分包括如下的内容:
评估系统的业务流程 业务种类 架构体系
各个企业的产品不同,业务⽅向不同,程序代码不同,系统架构更不同对于各个地⽅的细节 都需要有⼀定程度的认知 才可以开起设计的源头
分类出所需的监控项种类
⼀般可分为 : 业务级别监控 / 系统级别监控 / ⽹络监控 / 程序代码监控/ ⽇志监控 / ⽤户⾏为分析监控/ 其他种类监控⼤的分类 还有更多的细⼩分类这⾥给出⼏个例⼦
* 业务监控可以包含 ⽤户访问QPS,DAU⽇活,访问状态(http code), 业务接⼜(登陆,注册,聊天,上传,留⾔,短信,搜索),产品转化率,充值额度,⽤户投诉 等等这些很宏观的概念(上层)
* 系统监控 主要是跟操作系统相关的 基本监控项 CPU/ 内存 / 硬盘 / IO / TCP链接 / 流量 等等(Nagios – plugins, prometheus)
* ⽹络监控 (IDC)对⽹络状态的监控(交换机,路由器,防⽕墙,VPN) 互联⽹公司必不可少 但是很多时候又被忽略 例如:内⽹之间(物理内⽹,逻辑内⽹ 可⽤区 创建虚拟机 内⽹IP )外⽹ 丢包率 延迟 等等
* ⽇志监控 监控中的重头戏(Splunk,ELK),往往单独设计和搭建, 全部种类的⽇志都有需要采集 (syslog, soft, ⽹络设备,⽤户⾏为)
* 程序监控 ⼀般需要和开发⼈员配合,程序中嵌⼊各种接⼜ 直接获取数据 或者特质的⽇志格式
监控技术的⽅案/软件选取(主观因素)
* 各种监控软件层出不穷,开源的 商业的 ⾃⾏开发的 ⼏百种的可选⽅案
* 架构师凭借⼀些因素 开始选材.
* 针对企业的架构特点,⼤⼩,种类,⼈员多少 等等 选取合适的技术⽅案
监控体系的⼈员安排
* 运维团队的任务划分,责任到⼈,分块进⾏
* 开发团队的配合⼈员选取,很多监控涉及的⼯作 都需要跟开发⼈员配合 才可以进⾏
监控系统的搭建
• 单点服务端的搭建(prometheus)
• 单点客户端的部署
• 单点客户端服务器测试
• 采集程序单点部署
• 采集程序批量部署
• 监控服务端HA / cloud (⾃⼰定制)
• 监控数据图形化搭建(Grafana)
• 报警系统测试(Pagerduty)
• 报警规则测试
• 监控+报警联合测试
• 正式上线监控
数据采集的编写
可选⽤脚本作为数据采集途径
例如: shell / python / awk / lua (Nginx 安全控制,功能分类)/ php / perl/ go 等等
shell : 运维的⼊门脚本,任何和性能/后台/界⾯⽆关的逻辑 都可以实现最快速的开发(shell 是在运维领域⾥ 开发速度最快 难度最低的)
python: 各种扩展功能 扩展库 功能丰富 ,伴随各种程序的展⽰+开发框架(如django)等 可以实现快速的中⾼档次的平台逻辑开发. ⽬前在运维届 除去shell这个所有⼈必须会的脚本之外,⽕爆程度就属python了
awk: 本⾝是⼀个实⽤命令 也是⼀门庞⼤的编程语⾔. 结合shell脚本 或者独⽴ 都可以使⽤。在⽂本和标准输出处理上 有很⼤的优势
lua: 多⽤于nginx的模块结合 是⽐较新型的⼀个语⾔
php:⽼牌⼦的开发语⾔,在⼤型互联⽹开发中,⽬前有退潮的趋势 (PHP语⾔,php-fpm)不过在运维中⼯具开发还是很依赖PHP
perl: 传说中 对⽂本处理最快的脚本语⾔ (但是代码可读性不强)
go: 新型的语⾔ ⽬前在开发和运维中 炒的很热 ⼯资也⾼ C语⾔在各种后端服务逻辑的编写上开发速度快成⾏早
作为监控数据采集, 我们⾸推 shell + python , 如果说 数据采集选取的模式 对性能/后台/界⾯ 不依赖,那么shell速度最快 成本最低(公司往往喜欢快的)
数据采集的形式分类
⼀次性采集:
例如我们使⽤⽐较简单的 shell ./monitor.sh (ps -ef | grep, netstats -an | wc )+ crontab的形式按10秒 / 30秒 / ⼀分钟 这样的频率去 单次采集。
优点:⼀次性采集的模式 稳定性较好 不容易出现各种错误 和性能瓶颈,且开发逻辑简单 实现快速
缺点: ⼀次性采集 对于有些采集项⽬ 实现起来不够智能 也不够到位 例如 ⽇志的实时采集(使⽤⼀次性采集 ⽇志⽂件 200/5xx diff grep 也可以实现 但是很low 不够准确 不够直观)
后台式采集:
采集程序以守护进程运⾏在Linux后台,持续不断的采集数据: pormetheus exporter 例如python/go开发的daemon程序 后台持续不断的采集
优点: 后台采集程序 数据准确性⾼ 采集密度精细 管理⽅便
缺点:后台采集程序 如果开发过程不够仔细 可能会出现各种 内存泄漏 僵⼫进程 性能瓶颈的问题, 且开发周期较长
桥接式采集:
本⾝以后台进程运⾏ 但是采集不能独⽴ 依然跟服务器关联 以桥接⽅式收集采集数据
例如:NRPE for nagios
监控数据分析和算法
例如: 采集CPU 的七种 等待状态参数 , 采集⽤户每秒访问请求量 QPS对于这些”基本单位”的数据采集 本⾝是必须的 也是没有疑问的
但是这⾥有⼀个问题,采集回来的单位数据 如果没有懂⾏的⼈ 将它们形成 监控公式 和 报警阈值 那采集数据就没有任何的意义了
CPU来举例

如果作为⼀个运维架构师 不懂得 Linux中CPU各种参数的深⼊原理例如 平均负载是如何计算的,CPU的时间⽚分布是如何分类的,什么叫作 ⽤户态/内核态 CPU等待/处理时间 什么是 Interuptable/uniteruptable CPU等待等等这些概念。 那么即便数据被采集回来的再精细准确 你也利⽤不好
所以监控的数据分析和算法 其实⾮常依赖 运维架构师对Linux操作系统的各种底层知识的掌握
如果 我们使⽤那种⽼式的傻⽠式的监控 如nagios , ⾥⾯的监控脚本很全⾯(shell sh return, bin),⽣成报警规则 和 阈值也很简单,缺点却显⽽易见: 监控的太粗糙 实⽤性不强(例如:naigios 监控中 对CPU⾼不⾼的监控判断 就依据⼀个 当前的load值 >5 就警告 >10就报警, 我请问这种⽅式的CPU报警 有什么意义么? 有利于我们通过监控找到真正的问题么?)
另外还有⼀个问题例如业务级别监控的算法 运维⾃⾝⽆法做到⼗分专业,因为本⾝跟操作系统⽆关,是跟数据算法相关举个例⼦:如果我想通过Prometheus实现对⽤户访问QPS的 精确监控那么对于 监控图形 曲线 QPS上涨 QPS下跌,QPS凸起,QPS和历史数据的⽐较⽅法 等等这些 都属于业务级别的监控阈值类型
需要有专业的数据分析⼈员的协助 才可以算出优良的算法
例如: 如果我现在想针对 当前QPS下跌率进⾏报警计算, 那么⽤什么养的公式 针对我们的业务类型更贴切?我是选择 计算当前5分钟内的平均值 当 < ⼀个固定数值的时候 报警合适?我是选择 计算当前10分钟的总量 然后和 前⼀个⼩时同⼀时段⽐较合适?我是选择 计算当前⼀⼩时的平均值 和 过去⼀周内 每⼀天的同⼀时段的时间⽐较合适?艺体类推,这些数据算法 本⾝跟Linux⽆关,只有⾮常专业的 数据计算团队 才可以给出⼀个最合理的算法 协助我们的报警规则
监控稳定测试
不管是⼀次性采集,还是后台采集,只要是在Linux上运⾏的东西 都会多多少少对系统产⽣⼀定的影响,稳定性测试 就是通过⼀段时间的单点部署观察 对线上有没有任何影响
监控⾃动化
监控客户端的批量部署,监控服务端的HA再安装,监控项⽬的修改,监控项⽬的监控集群变化种种这些地⽅ 都需要⼤量的⼈⼯,⾃动化的引进 会很⼤程度上 缩短我们对监控系统的维护成本
这⾥给出⼏个实例: Puppet(配置⽂件部署),Jenkins(CI 持续集成部署) , CMDB(运维⾃动化的最⾼资源管理平台 和 理念 )。。。。等等 利⽤好如上这⼏个聚的例⼦,就可以实现 对监控⾃动化的掌控
监控图形化⼯作
采集的数据 和 准备好的监控算法,最终需要⼀个好的图形展⽰ 才能发挥最好的作⽤监控的设计搭建需要⼤量的技术知识,但是对于⼀个观察者来说(⽼板),往往不需要多少技术,只要能看懂图就好(例如 ⽼板想看看 当前⽤户访问量状况,想看看 整体CPU⾼不⾼ 等等)所以 , 监控的成图⼯作 也是很重要的⼀个内容
企业监控通⽤用技术
介绍企业⽬前在监控上的各个发展阶段
早期企业⽆监控 (路远靠⾛ 安全靠狗 ^_^)全部都是⼈⼯盯着 服务器 操作系统 软件 ⽹络 等等
中前期企业 半⾃动脚本监控
利⽤shell脚本这种类似的形式,做最简单的监控脚本
循环登陆机器 查看⼀些状态 之后⼈⼯记录
⽆报警 ⽆⾃动化 ⽆监控图形
中期企业 ⾃动化程序/脚本/软件/监控
脚本更新换代 开始使⽤各种开源⾮开源软件 程序 进⾏监控的搭建和开发
监控形成图形化,加⼊报警系统 ,有⼀定的监控本⾝⾃动化实现
这个阶段监控开始逐步成型 但是仍然缺乏精确度和稳定程度 报警的精细度
中后期企业 集群式监控 各种外援监控⽅案
监控开始⾃成体系 加⼊各种⾃动化
除去⾃⾝开发和搭建监控系统外,还会⼤量使⽤各种外围监控 (各种商品监控 例如云计算监控 监控宝友盟等等)
监控发展出 内监控+ 外监控(内监控是企业⾃⼰搭建的⾃⽤监控, 外监控是 使⽤外援的商业监控产品 往往对产品的最外层接⼜和⽤户⾏为进⾏更宏观的监控)
当前和未来监控未来的监控 主要会在⼏个⽅⾯ 不断的提⾼
监控准确性 真实性
监控⾼度集成⾃动化 ⽆⼈值守
监控成本的⽇益降低
监控和CMDB的集成化以及⾃愈系统的发展
介绍企业当前实⽤的通⽤技术和⼯具
脚本监控(当前依然使⽤最原始的 脚本运⾏的形式 采集和监控的公司 依然不在少数 很多时候是为了节约成本)
开源/⾮开源⼯具监控 如:Nagios / Cacti / icinga / Zabbix / Ntop / prometheus / 等等。。
报警系统 : Pagerduty / ⾃建语⾳报警系统 / ⾃建邮件系统/ ⾃建短信通知 / 各种商业报警产品
企业监控⽬前⾯临的⼀些问题
• 监控⾃动化依然不够
• 很少能和CMDB完善的结合起来
• 监控依然需要⼤量的⼈⼯
• 监控的准确性和真实性 提⾼的缓慢
• 监控⼯具和⽅案的制定 较为潦草
• 对监控本⾝的重视程度 依然有待提⾼ (其实是最糟糕)
介绍监控的未来最终理想化
完整⾃愈式监控体系
监控和报警 总归还是只能发现问题。 出现问题之后的处理 依然需要⼈⼯的⼤量⼲预
未来当⾃愈系统完善之后,各种层级的问题 都会被各种⾃动化 持续集成 ⼈⼯智能 灾备 系统缓冲 等等技术⾃⾏修复
真实链路式监控
监控和报警的准确性 真实性 发展到最终级的⼀个理想化模型
举个例⼦: 当系统发出报警信息后,往往是各个层级的报警 ⼀⼤堆⼀起发出 把真实引起问题的地⽅掩盖住⾮常不利于我们即时的发现和处理问题。例如:真实发⽣的问题 是在于 数据库的⼀个新的联合查询 对系统资源消耗太⼤造成各个⽅⾯的资源被⼤量消耗 间接的就引起各种链路的问题。于是乎 各个层⾯的报警 接踵⽽⾄, ⽇志在报警,慢查询在报警,数据库CPU 内存报警, 程序层TCP链接堆积报警,HTTP返回码5xx 499报警。所有系统CPU 缓存报警, 企业级监控⽤户流量下降报警种种⼀堆⼀堆被连带出来的报警 全都暴露出来了,结果真正的背后原因 这⼀个祸根的DB查询反⽽没有被监控发现 或者说发现了 但是被彻底淹没了
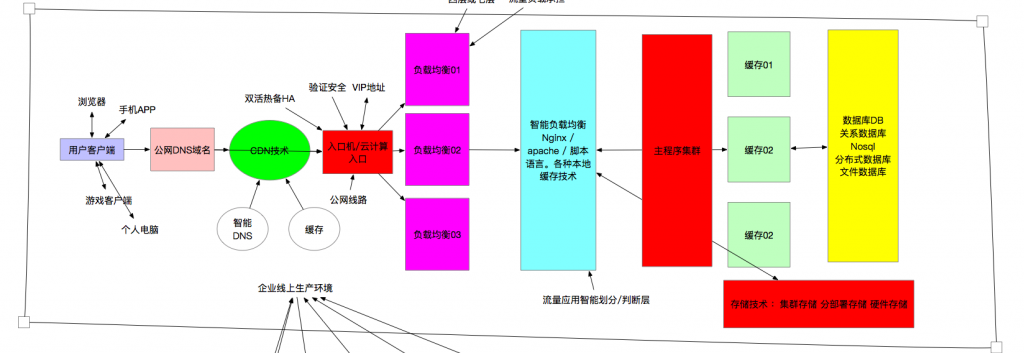
最终理想的未来报警系统 可以把所有⽆关的报警全部忽略掉,以链路的⽅式 对问题⼀查到底 把最终引起问题的地⽅ 报警出来 让运维和开发 即时做出响应和处理
发布者:LJH,转发请注明出处:https://www.ljh.cool/7205.html